


- Karol Sobota
- Read in 7 min.
Applying the right algorithm for certain business requirements may prove time-consuming and complex – especially if the application is used for solving specific planning issues, such as dynamically generating work schedules, automatically assigning tasks to team members, or marking the optimal route between multiple stops.
An interesting solution to this problem could be the usage of tools which are based on the artificial intelligence algorithms. They make it possible to automatically solve a certain issue while taking into account a set of pre-defined limitations. Such tools are called Constraint Solvers and one of them, which is accessible in Java, is Optaplanner library which is available at optaplanner.org.
In this article we will walk through the specification of this library. We are going to take a closer look at one of the issues which can be solved with it, and describe an exemplary implementation of such solution in the Spring Boot framework.
An example of a planning issue
One of the exemplary planning issues is automatic assignment of tasks to certain employees. Before we implement the solution, let us analyze the problem’s characteristics closer.
On the figures below we can see a chart which represents team members’ work schedule in a specific day (Fig 1) followed by a list of tasks that need to be completed (Fig 2).
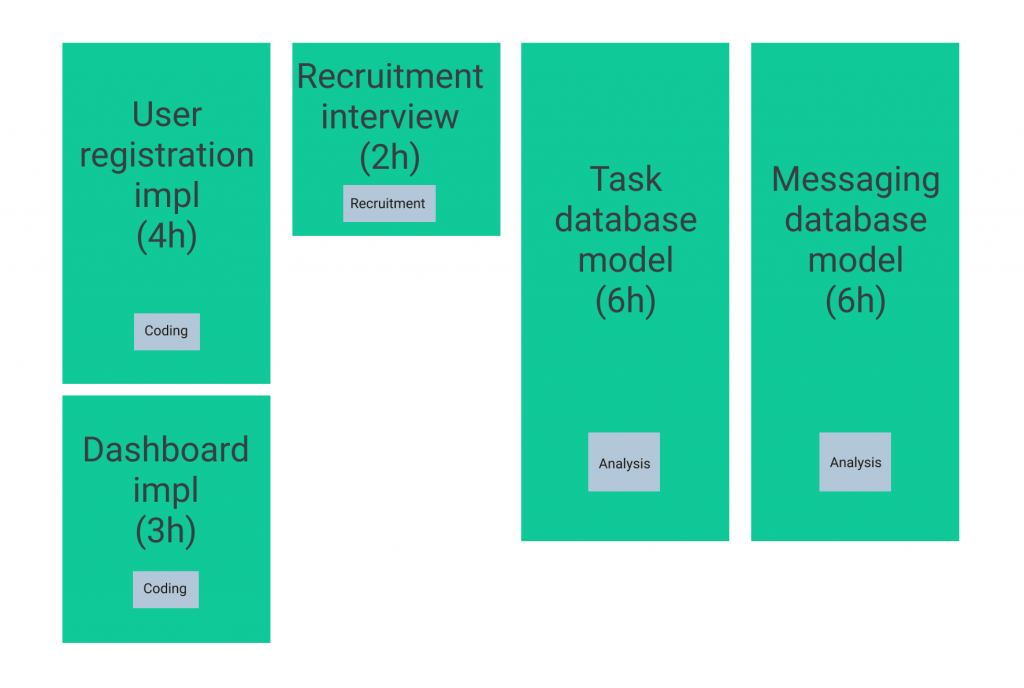
The problem that needs to be solved here is assigning all of the tasks to the team members in such a manner, so that all of them are completed in one day.
In order to simplify the issue let us assume that each person works eight hours a day, and everyone works in the same time slot.
Therefore, one of the limitations is as follows: after assigning all of the tasks, each person’s working time cannot be longer than eight hours. What is more, each task is connected with one of the three listed categories: Coding, Analysis oraz Recruitment. In order for a specific worker to be able to complete a certain task, they must have the right skills for the job.
While dealing with the problem in a classic, iterative manner, we would start with assigning the first task from the list to the first person. Since John has the right Coding skills, User registration impl would go straight to him.
The next task is also connected with the Coding category. It is expected to take three hours to complete, therefore it is not against any limitation for it to be assigned to John as well.
The third task belongs to the Recruitment category, so it has to be assigned to someone else than John since he does not have the right set of skills in order to complete it. It is expected to last two hours, so upon assigning it to John it would also exceed the time limit. Therefore the Recruitment interview task goes to Brian, as he meets all the necessary criteria.
After analyzing the following task in a corresponding manner, we assign it to Freddie. At this point the working schedule looks as follows:
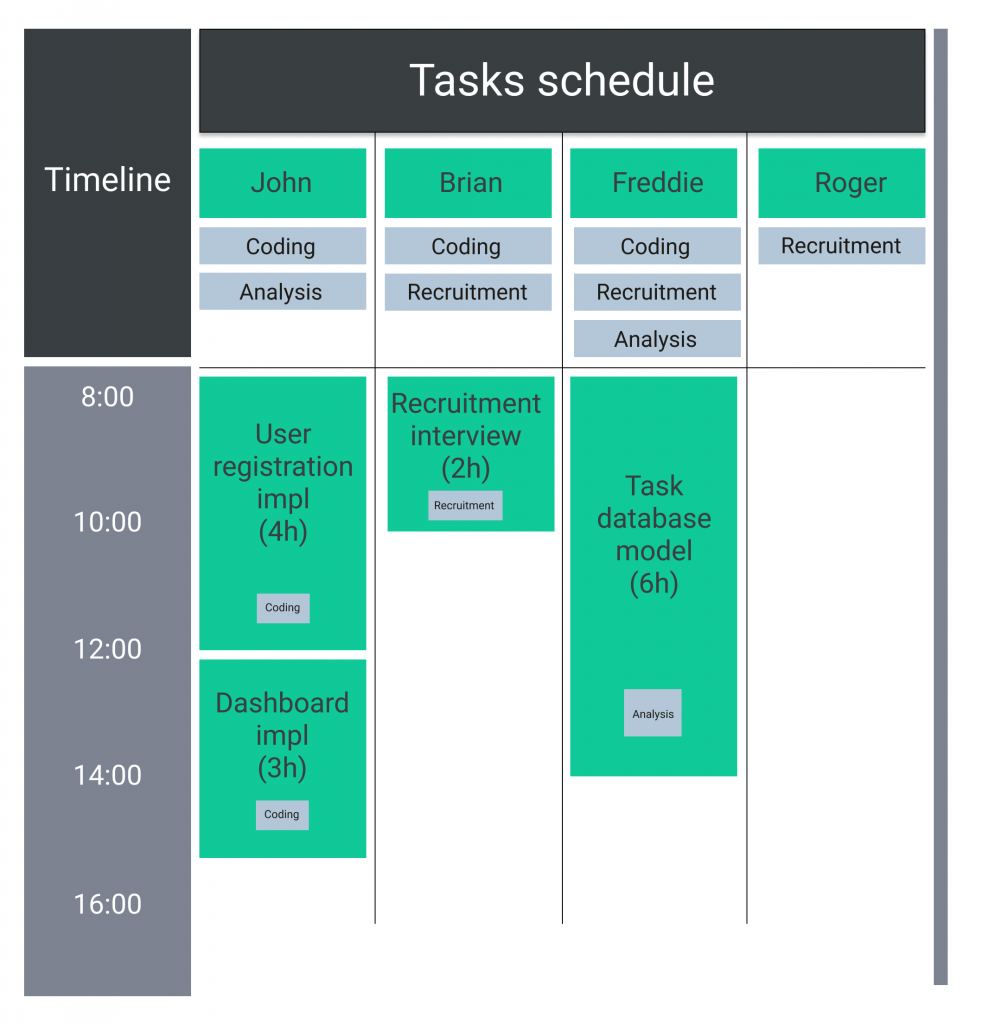
Here we are forced to pause, as we only have one task left to assign: Messaging database model. Due to the pre-defined limits we cannot assign it to any of the workers. The only people who have enough working time at their disposal are Brian and Roger, however none of them has the right skills in the Recruitment category.
In this situation we are forced to start over, and try to assign the tasks differently. After a few attempts we manage to finally solve the problem. An exemplary solution could be:
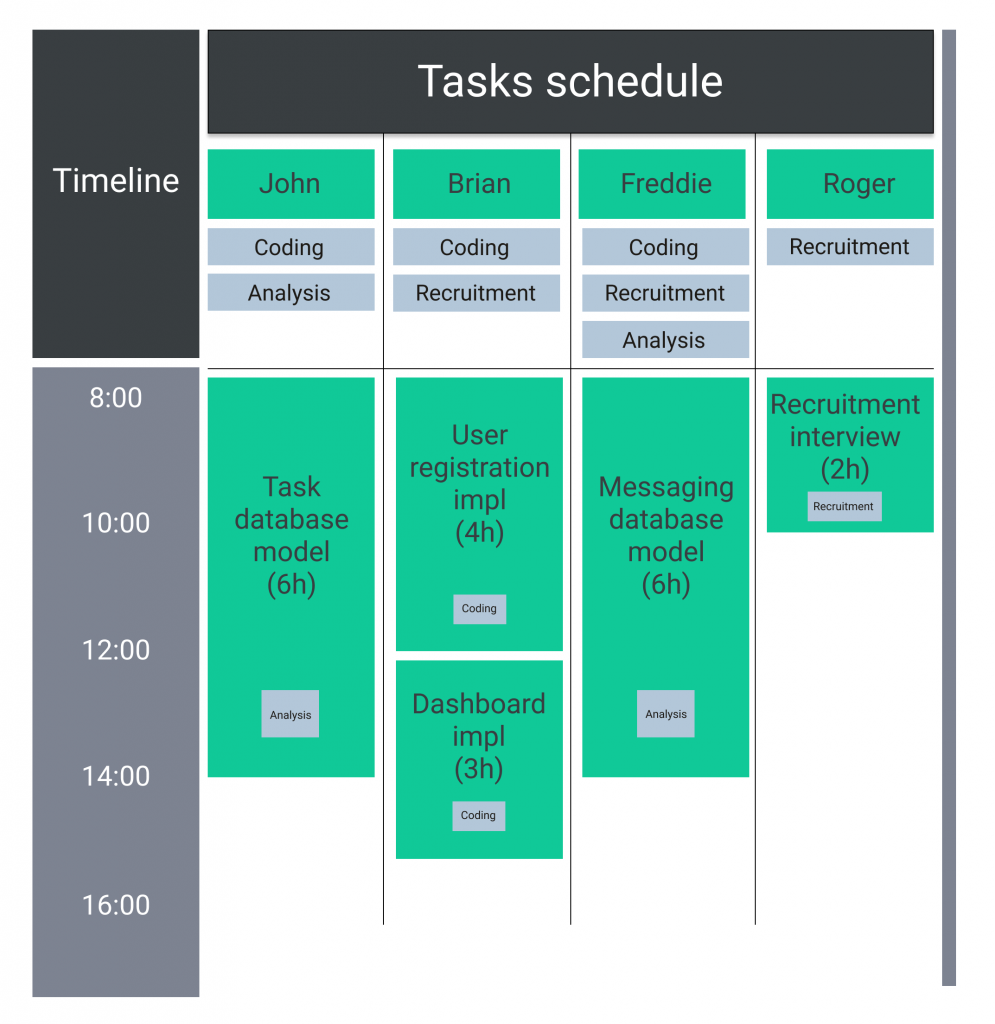
At this point the issue might seem quite innocent, however we must bear in mind that it is only a simplified example. In reality not only the number of people, but also the list of tasks could be much bigger, and what is more, further limitations might surface.
Let us assume that we must not only verify the task categories and working time of each person, but also minimize the differences between each person’s working time in order to optimize the schedule. What is more, some employees would work for a few consecutive hours a day, and others would take breaks. In such a situation implementing the right solution becomes more and more complex, and the number of iterations necessary to obtain the right solution grows rapidly. This could easily lead to efficiency issues.
After engaging ourselves in task assigning, we probably would reach an effective solution at one point, however it would cost us a lot of time. In order to avoid it, let us try to solve the problem with OptaPlanner.
The methods of OptaPlanner
Before we focus on the code implementation, let us take a look at the tool’s working manner. In order for a specific issue to be solved by this tool, it has to be clearly described.
One of the key elements which OptaPlanner requires are the planning entities. Just like the classic database entities, they are used to represent the imaginary or real objects which are describing specific issues. The planning entities also contain information on whether certain objects can be modified in order to achieve the optimal solution or not.
Two classic entities are represented in the charts below. They contain elements of the planning issue which we described earlier.

In order for those entities to be applicable to OptaPlanner, a few extra elements must be added to them. The most important step is selecting the planning entity. In that way OptaPlanner knows which parameters of an object can be shifted while generating one of the possible solutions to the problem. In Spring Boot we mark the planning entity by adding @PlanningEntity.
In the analyzed example of assigning tasks to team members, Task entity is the planning entity. As only one entity can be marked in that way, the Employee entity does not need to be modified at all.
As could have been noted before on the example of schedules, it was the positions of the tasks that were modified while the other elements remained untouched. For us, the task positions on the charts provide information that we interpret in a specific way, whilefor OptaPlanner it has to be some parameter that can be shifted. In our case that parameter was the employee assigned to a specific task, and just like before, this piece of information has to be noted correctly in the Task entity. Such parameters are called planning variables andwe mark them by adding @PlanningVariable annotation.
As there may be multiple tasks of identical parameters, OptaPlanner needs to be able to differentiate between them while assigning them to one of the employees. The element that makes it possible, and needs to be taken into consideration, is the planning variant identifier which in Spring Boot it is marked through @PlanningId annotation.
On the figure below we can see an example of modified entities which can be used in OptaPlanner.

While working, OptaPlanner generates multiple variants of the solution to the problem. Since the tool is expected to find one optimized solution, generated results need to be compared, so that the best option could be selected. In order to do that, OptaPlanner uses a score calculating mechanism that defines a set of rules. This leads to assessing which feature affects the solutions’ efficiency. The defined rules can either add or subtract a number of points. What is more, there might be more than one score weight. Examples of such rules are as follows:
- If a task is assigned to a person who does not have the right skills to complete it, two points need to be subtracted from this solution
- If each person has at least one task assigned, one point needs to be added to this solution
The final score of the generated variant can have multiple forms, and be grouped into different categories. The most common one is the Hard/Soft score. After generating two exemplary solutions to a problem, one of them might score -10 Hard and +2 Soft points, and the other one -1 Hard and 0 Soft points. Since the Hard category is the priority, the second solution will be chosen as optimal.
The information about the score of each variant is stored in the planning solution class, alongside with the input data and output data which form a set of solution elements.
In order for the generated solutions to be valuable, the rules defining the calculation of points need to be as specific as possible. Otherwise a solution that breaks even a few critical rules by the algorithm might be considered as optimal.
OptaPlanner Implementation In Spring
After the long theoretical introduction we may finally move forward to the implementation of the solution of the earlier defined problem.
In order to start using the OptaPlanner library, we need to add to our project the OptaPlanner Spring Boot Starter dependency:
<dependency>
<groupId>org.optaplanner</groupId>
<artifactId>optaplanner-spring-boot-starter</artifactId>
<version>8.16.0.Final</version>
</dependency>
The newest version of the library can be found under this link.
Next, just like in theory, we begin the implementation with forming entities that will later represent specific objects. Those entities are the following:
Task.java
@PlanningEntity
public class Task {
@PlanningId
private Long id;
//attributes
private String description;
private Integer estimatedHours;
private Skill requiredSkill;
//planning variables
@PlanningVariable(valueRangeProviderRefs = "employeeRange")
private Employee employee;
}
Employee.java
public class Employee {
private String name;
private String surname;
private Integer workHours;
private List<Skill> skillList;
private Integer hoursWorked = 0;
}
As we can see in the code fragments above, the OptaPlanner library annotations were only added in the Task class. Those are respectively:
- @PlanningEntity – marking an entity as the leading, planning one
- @PlanningId – marking the id attribute as an planning variables identifier
- @PlanningVariable(valueRangeProviderRefs = “employeeRange”) – marking the Employee entity as the planning variable. The valueRangeProviderRefs parameter will be used in the class representing the planning solution
The next step is to define the list of rules which will later be used in order to calculate the score of a specific solution. A fragment of such created list of rules might look as follows:
ScheduleConstraintProvider.java
public class ScheduleConstraintProvider implements ConstraintProvider {
@Override
public Constraint[] defineConstraints(ConstraintFactory constraintFactory) {
return new Constraint[]{
// Hard constraints
skillRequired(constraintFactory),
workHoursConflict(constraintFactory),
// Soft constraints
employeeTimeEfficiency(constraintFactory),
employeeTimeEfficiency2(constraintFactory)
};
}
private Constraint workHoursConflict(ConstraintFactory constraintFactory) {
// An employee cannot operate for more than 8 hours.
return constraintFactory.forEach(Task.class)
.groupBy(Task::getEmployee, ConstraintCollectors.toList())
.filter((a, b) -> b.stream().mapToInt(Task::getEstimatedHours).sum() > a.getWorkHours())
.penalize("Work hours conflict", HardSoftScore.ONE_HARD);
}
private Constraint skillRequired(ConstraintFactory constraintFactory) {
// An employee must have required skill to complete given task.
return constraintFactory.forEach(Task.class)
.filter(t -> !t.getEmployee().getSkillList().contains(t.getRequiredSkill()))
.penalize("Skill required", HardSoftScore.ONE_HARD);
}
private Constraint employeeTimeEfficiency(ConstraintFactory constraintFactory) {
// An employee should have at least one task every day.
return constraintFactory.forEach(Task.class)
.groupBy(Task::getEmployee, ConstraintCollectors.toList())
.filter((a, b) -> b.stream().mapToInt(Task::getEstimatedHours).sum() > 0)
.reward("employeeTimeEfficiency", HardSoftScore.ONE_SOFT);
}
private Constraint employeeTimeEfficiency2(ConstraintFactory constraintFactory) {
// An employee should work 8 hours per day.
return constraintFactory.forEach(Task.class)
.groupBy(Task::getEmployee, ConstraintCollectors.toList())
.filter((a, b) -> !(b.stream().mapToInt(Task::getEstimatedHours).sum() < 8))
.reward("employeeTimeEfficiency2", HardSoftScore.ONE_SOFT);
}
}As we can see in the extract above, the list of pre-defined rules is located in the class that implements ConstraintProvider interface. This interface generates an array of Constraint elements, which are, in fact, our rules.
There are two punishing and two rewarding rules implemented in the example above. The penalty is given to a solution when a task gets assigned to an employee who does not have the right skills to complete it, and also while the aggregated number of hours required to complete the tasks exceeds the working time of a team member. From the other hand the reward is given for assigning the tasks in such a manner that the working time of each person is accumulated to roughly eight hours per day.
The next element that we need to define is the class which represents the planning solution. A fragment of the code with an implementation of such class might look as such:
Schedule.java
@PlanningSolution
public class Schedule {
@ValueRangeProvider(id = "employeeRange")
@ProblemFactCollectionProperty
private List<Employee> employeeList;
@PlanningEntityCollectionProperty
private List<Task> taskList;
@PlanningScore
private HardSoftScore score;
}
The annotations used here bythe OptaPlanner are:
- @PlanningSolution – marking an entity as the class used for planning solution
- @ValueRangeProvider(id = “employeeRange”) – a list marked with this annotation contains elements which can be used by the planning variable
- @ProblemFactCollectionProperty – this marks a list as the input data for the planning problem. Those elements cannot be changed during solutions generation
- @PlanningEntityCollectionProperty – this marks a list as a set of generated elements which represent the planning entities
- @PlanningScore – this element contains data on the score of each solution
The last element that we must implement is the definition of a Solver, which will initiate generating solutions to our problem. In the code it might be represented as follows:
@Autowired
private SolverManager<Schedule, UUID> solverManager;
public Schedule solve() {
Schedule problem = Schedule.builder()
.employeeList(list_of_employees)
.taskList(list_of_tasks)
.build();
UUID problemId = UUID.randomUUID();
// Submit the problem to start solving
SolverJob<Schedule, UUID> solverJob = solverManager.solve(problemId, problem);
Schedule solution;
try {
// Wait until the solving ends
solution = solverJob.getFinalBestSolution();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException("Solving failed.", e);
}
return solution;
}
The solution represented above expects the process of generating new variants to be stopped manually, which is why we need to add the following feature to the application.properties configuration:
optaplanner.solver.termination.spent-limit=1s
In that way after one second we will receive a solution which has scored the highest Hard/Soft number of points. This length of time is enough to find the optimal solution in our problem, however in case of more complex issues the process might even take a few minutes. In such a case it might be reasonable to add a recurring verification of the best variant in a specific moment instead of setting a solution generating limit. In that way we might find an acceptable solution sooner, and then pause the process manually.
Summary
The Constraint Solvers tools are an interesting alternative to solving certain planning problems. In our opinion their great strength is the fact that problem solving is dealt with in a declarative manner, which means that it is the outcome that needs to be pre-defined, not the process. Thanks to that, after some practice in describing the problems using planning entities and sets of limitations, we are able to solve more issues in the same amount of time.
Check out other articles in the technology bites category
Discover tips on how to make better use of technology in projects



