


- Mariusz Kujawski
- Read in 4 min.
In today’s article, I will show how to set up an environment to be able to query the data lake and process information in Azure.
Let’s look at Azure Synapse components such as:
- Spark Pool used for data processing
- Serverless Pool used to query the data in the data lake built on top of Azure Data Lake.
Synapse Lake database is a more natural approach to query data than the OPENROWSET command that we can use in Serverless Pool. I’ll show how to create tables using Spark to avoid extra steps and prepare data in a medallion architecture.
Azure Data Lake
Azure Data Lake is a storage service provided by Azure Cloud. It is an extremely cost-effective storage solution, where data can be collected in a hierarchical file system (unlike blob storage, where data are kept in a totally flat structure). It provides support for permission management for separate folders, like in a computer file system.
Azure Synapse
Azure Synapse is an analytics service offered by Azure Cloud. It provides the ability to load, manipulate, and analyze data. It offers a few parts which work together to create an analytical platform that offers:
- Pipelines – for orchestrating data processing
- Data Flow – for carrying out data manipulation without writing any code
- Spark (Notebooks and Jobs) – for combining live code (using Python, Scala, .NET or Spark SQL)
- SQL Serverless (SQL-on-demand) – for querying data using a SQL
- SQL Pools – for deploying a dedicated SQL Data Warehouse
Synapse Serverless SQL
Serverless SQL pool is a part of Azure Synapse Analytics workspace, which can be used to query data in the Azure Data Lake. It supports formats like Parquet, Delta, CSV. You can query data directly from a data lake using T-SQL syntax. Serverless SQL pool is a distributed data processing system. It has no infrastructure to configure or clusters to maintain. The default endpoint for this service is provided within every Azure Synapse workspace, so you can start querying data as soon as the workspace is created. You will only be charged for this service for data processed by your queries.
The Azure Synapse Analytics workspace enables you to create two types of databases on top of a data lake:
- Lake databases – where you can define tables on top of a data lake using Apache Spark. This table will be available to query using Spark and Serverless Pool.
- SQL databases – where you can define your own databases and tables directly using the serverless SQL pools. You can use T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE to define the objects and add additional SQL views, procedures.
In this article, I’ll focus on Lake databases and integration with Apache Spark.
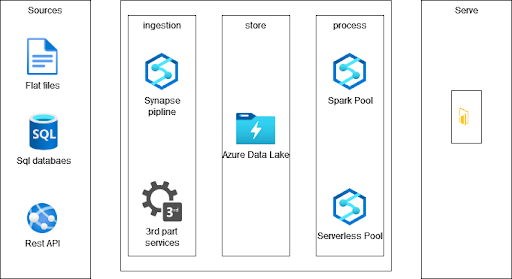
Architecture for a small business solution
Let’s assume that we deliver a small solution for a small company. In this case, we can extract data from source systems using Synapse Integration or third-party tools that will extract data from Oracle, SQL database, ERP, CSV files, or financial systems like SAP. These tools will ingest data into the first layer of our data lake –- the raw layer. Then we will use the spark pool to clean our data and save it in the silver layer. In the end, we aggregate the data and store it in the gold layer. To query our data from the data lake, we use Serverless pool and Power BI to present visualizations.
Spark Pool transformations
Just like in other Cloud platforms, Azure gives us a Spark engine that we can use to process files. We have the raw layer where we keep files that are in CSV format and require a cleaning process that will prepare files for querying. I use PySpark to transform data, change column names, convert data types, filter data, and save it to a table and in parquet format.
To simulate the transformation process, I’ll execute the script below. The script reads data from CSV, removes spaces between numbers and renames column names.
from pyspark.sql.functions import *
df = spark.read.load('abfss://raw@xxx.dfs.core.windows.net/stocks/stocks/', format='csv'
, header=True
)
df = df.withColumnRenamed("v", "value")
df = df.withColumn("value", regexp_replace(col("value")," ","")) \
display(df.limit(50))When we finish with transformations and obtain the required result, we are ready to execute the code that will create a table. The table can be used as a source for queries in the Serverless Pool.
df.write.format("parquet") \
.mode("overwrite") \
.partitionBy("ticker") \
.option("path", "abfss://silver@xxx.dfs.core.windows.net/stocks/") \
.saveAsTable("stocks")
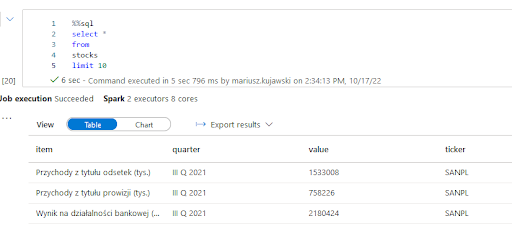
You can check your table by opening a new Notebook and writing a query that will present data from the new table.
The query using Spark Pool:
The query using Serverless Pool:
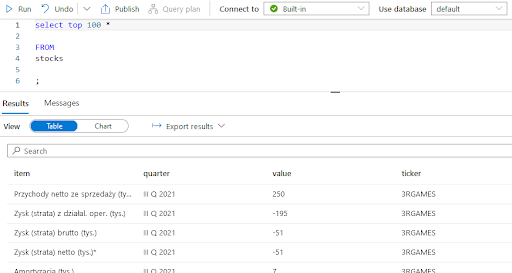
As you can see, Serverless Pool uses T-SQL notation to query data. Hover, we pay here only for processed data, not for a running cluster like in the case of Spark Pool.
Data processed by the query:
Total size of data scanned is 1 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
We can also create a Lake database and configure default settings like a file path and a format. You can find these settings in Synapse Workspace.
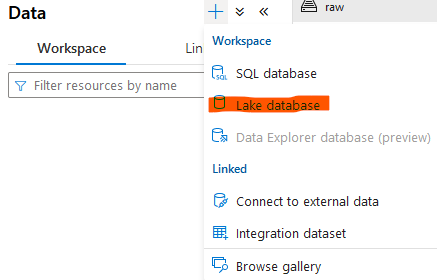
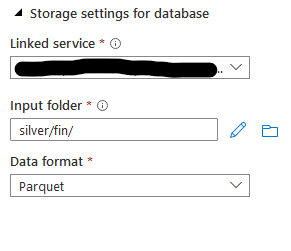
Now we can execute the script that will transform data and create a table in the new database and save data in the data lake.
%%pyspark
from pyspark.sql.functions import *
df = spark.read.load('abfss://raw@xxx.dfs.core.windows.net/stocks/prices/', format='csv'
## If header exists uncomment line below
, header=True
)
df = df.select(
col("Spolka").alias("company"),
col("Waluta").alias("currency"),
col("C_otw").alias("open"),
col("C_max").alias("max"),
col("C_min").alias("min"),
col("Cena zamknięcia").alias("close"),
col("Data").alias("date")
)
display(df.limit(5))
df.write.saveAsTable("fin.prices")When you execute the script, you should see the new table in Synapse Workspace like in the screen below.
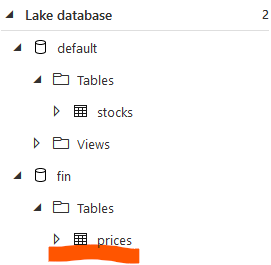

Spark table types in SQL
As presented, Apache Spark allows you to create two main types of tables that Azure Synapse exposes in SQL automatically:
- Managed – Spark manages both the data and the metadata. These files are normally held in the warehouse directory, where managed table data is stored.
- External – Spark only manages the metadata, but requires you to specify the exact path where you want to store information. Spark also provides ways to create external tables over existing data.
To observe main differences, you can drop booth tables:
- Dropping a managed table, Spark will delete both files in the data lake and the table metadata in the meta-store.
- Dropping an external table, Spark will just delete the metadata. It means that you won’t be able to query the table, but you will find your files in your data lake.
An alternative way to create tables is to use SparkSql.
The External table
%%pyspark
df = spark.read.load('abfss://raw@xxx.dfs.core.windows.net/stocks/stocks/', format='csv'
, header=True
)
df.createOrReplaceTempView("stocks_raw")
%%sql
CREATE TABLE stocks_2
USING Parquet
LOCATION 'abfss://silver@xxx.dfs.core.windows.net/stocks_2/'
AS
SELECT ticker, item, quarter, cast(value as integer) value
FROM stocks_raw
The Manage table
%%pyspark
df = spark.read.load('abfss://raw@xxx.dfs.core.windows.net/stocks/stocks/', format='csv'
, header=True
)
df.createOrReplaceTempView("stocks_raw")
%%sql
CREATE TABLE fin.stocks
AS
SELECT ticker, item, quarter, cast(value as integer) value
FROM stocks_raw
You can list tables in the lake database also using commands like below:

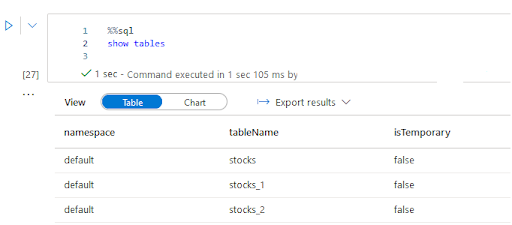
Summary
The Lake database is a convenient way to process and analyze data for an end-user. By creating descriptive metadata on top of your data lake, Lake Database organizes your files into tables and databases. This enables users to query objects that they are interested in without having to navigate through the data lake structure. Thanks to the integration with Apache Spark you maintain your metadata during the ingestion process, and you don’t need to create views or additional external tables like in the SQL database.
Check out other articles related to data engineering
Discover tips on how to make better use of technology in projects



