


- Mariusz Kujawski
- Read in 7 min.
Are you considering transitioning to a cloud environment? If so, one of the biggest challenges you might face is choosing the right cloud provider.
It’s important to be aware that building your entire cloud based data platform with tools from a specific company can make it challenging to switch providers in the future. Fortunately, there is a solution for building a cloud-agnostic data platform, which I’ll show in this article.
What is a Cloud Agnostic?
To optimize your cloud experience, it is important to adopt a Platform as a Service (PaaS) approach. With PaaS, you can reduce the cost of managing and maintaining your data platform by using the cloud provider’s SQL database instead of hosting your own server instance. Additionally, you can leverage microservices and containerization to streamline your applications. Using database engines, ETL tools and BI tools provided by the cloud provider, you can easily develop data pipelines, host data models and data lakes.
While simply moving virtual machines (VMs) to a specific cloud provider can bring some benefits, it can also limit the potential of the cloud. This is where the cloud-agnostic approach comes in for help.
A cloud-agnostic is an application, service, or process that is not tied to any specific cloud provider and can be used with any cloud or on-premises implementation. These are designed to work across various cloud platforms without requiring custom code or costly modifications, allowing organizations to deploy their applications and services in any environment.
Data processing
To leverage the power of data in your organization, you need to understand how to process, store, and serve your data. This activity can be divided into several phases:
- Ingesting data through batch jobs or streams. This process involves extracting data from internal and external sources. Data can be in two forms: batch and stream.
- Storing data in a data lake, data lakehouse, or data warehouse. Raw data is stored in the bronze layer of data lakes, then cleaned, deduplicated, and transformed into a common data format.
- Computing analytics and/or machine learning features. Computation can be a combination of batch and stream processing. Data is aggregated and prepared for data analysts, data scientists, and machine learning.
- Serving data in dashboards, data science, and machine learning. Data is presented in dashboards, reports, and consumed by AI/ML.
With cloud solutions, such activities necessary to create data platforms can be done without much effort.
Building a Cloud-Native Data Platform: Pros and Cons
With a serverless architecture, we can quickly develop a cloud based data platform using cloud-native resources.
The figure below illustrates a comparison of cloud based data platforms for AWS, Azure, and GCP. Using these components, we can migrate from an on-premise environment to the cloud, or from one provider to another. Having this flexibility allows us to select the right platform for our use case, implement it, and deliver business value for our customers/stakeholders and advanced analytics capabilities.
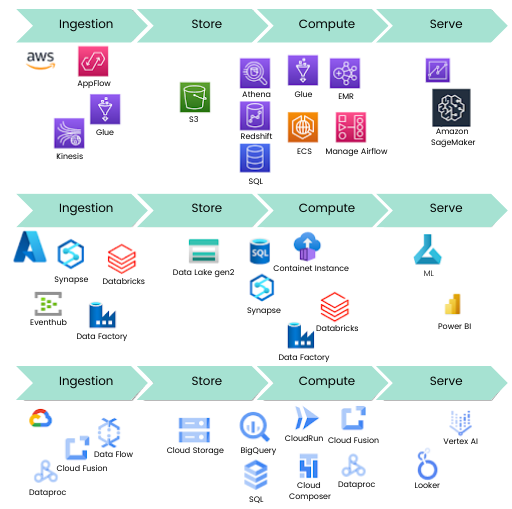
The approach above sounds great, but what are the disadvantages of the presented architecture? Let me introduce them, so you can see the full picture.
- Vendor lock-in.
- Developers may only be familiar with one technology provider in some cases.
- Cost of migration to another provider may be high.
These drawbacks don’t necessarily mean that the cloud-native approach is not for you. The advantages a particular provider can offer are:
- Easy integration of cloud-native resources with each other.
- Wide access to developers with the necessary skills.
- Streamlined implementation of new high-end features developed by the cloud provider.
However, if you want to be cloud agnostic, that’s not a problem. At Devapo, we can implement cloud-native as well as cloud-agnostic solutions for you. We will customize your architecture and facilitate the migration from your current provider to another. Additionally, we can keep more versatile skills on your team that will work on Azure, AWS and GCP.
How to build a Cloud Agnostic Data Platform?
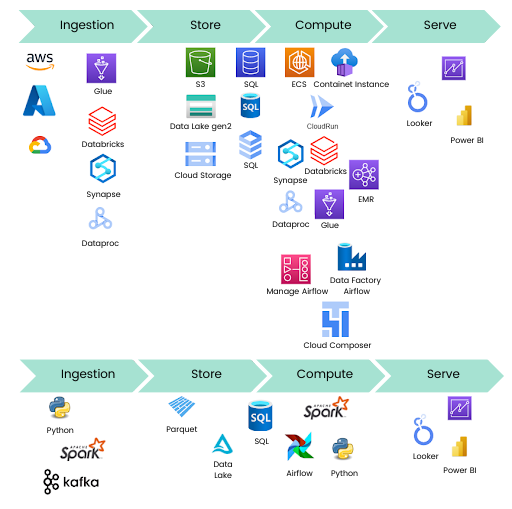
To make cloud agnostic data platform, we need a combination of software, tools, and programming languages that are available on other cloud platforms. There are four major universal languages: SQL, Python, Scala, and Java. The most popular platform for multi-parallel data processing is Apache Spark. The common way to store and process data is relational databases like MySQL, PostgreSQL, SQL Server, and Oracle. It is important to note that we can store data in popular file formats like Parquet, Avro, CSV, and Delta.
With this knowledge, we can focus on cloud resources that are built on these technologies. An alternative option is to use resources that are available on all three cloud platforms, like Databricks and Snowflake. It’s possible to use Databricks and Snowflake on AWS, Azure, and GCP, with only small differences in costs, functionalities, and data center locations where they are available.
SQL
We can store and host our data models on the cloud using popular SQL engines. With SQL or DBT, we can create ETL processes to make them portable. To build a traditional data warehouse, we could use serverless services like AWS RDS, AWS Aurora, Azure Database, and Cloud SQL. Cloud-agnostic databases that are offered include:
- PostgreSQL
- MySQL
- SQL Server
- Oracle
- Snowflake
With a solution built based on a SQL database, it’s possible for an organization to backup and restore databases on the same platform.
Data processing ETL/ELT
Apache Spark is a platform that utilizes a compute cluster to process data. It allows you to process data in batch and streaming modes. AWS, Azure, and GCP have their implementations of this engine, like AWS Glue, AWS EMR, Azure Databricks, Azure Synapse Spark Pool, and GCP Dataproc. These implementations allow us to use, for instance, PySpark to process data in a cluster or serverless manner. There are small differences in the implementation, but we are able to utilize standard Spark to be able to migrate it in the future. Moreover, Databricks is available on all three platforms. The alternative is to use its own cluster, but it can increase the costs of infrastructure.
With Python and other programming languages, we can create custom services to manipulate data using Pandas, for instance. We can dockerize our microservices. Then, we can host them in ECS, Container instance, or Cloud Run. This approach gives us the possibility to migrate our services and infrastructure to other providers without any effort. Besides, because we use code instead of drag and drop tools, we can create unit tests, end-to-end tests, test-driven development (TDD). With drag and drop tools, we develop using a graphical interface, and under-the-hood ETL tools generate JSON or XML.
With cloud environments, we can also use ETL/ELT tools where we can build our processes using graphical interfaces with drag and drop components to manipulate and orchestrate data. Below you can find a few of them. Some are open source, but there is also software that is not for free. These tools are cloud-agnostic, so you can work with different cloud providers:
- Apache NiFi
- Informatica Cloud Services
- Cloud Data Fusion
- Talend
Storage
Storage is probably the easiest area to migrate to. Files can be stored in the most popular formats and can be easily moved to other types of storage (S3, ADSL, Cloud Storage, HDFS, etc.). If we use, for instance, Databricks, we have to adjust the locations of the files. This migration can be more simple if we mount our storage on the cluster. A data lake is a very flexible and powerful way to store enormous amounts of data and make it cloud-agnostic. In many cases, we can read Parquet files using Databricks, BigQuery, Synapse, or Redshift. This allows us to use data virtualization. File migration tools are available through cloud providers, such as GCP’s Transfer Service.
Orchestration
Orchestration is another significant step in the development of the cloud based data platform. We can achieve it using Airflow, which is an orchestrator built with Python. Airflow is cloud-agnostic and available in AWS, Azure, and GCP as AWS Managed Airflow, Data Factory Airflow runtime, and Cloud Composer. Airflow can be installed on VMs or Dockers. Airflow’s workflows and DAGs are defined in Python code, so we can easily move it to another location.
As an alternative, we can implement Prefect or Dagster in our organization. For instance, Prefect offers an interesting way of implementation where the entire management is offered as PaaS, and we need to install agents or our infrastructure to execute our core.
Data management and DevOps
Data management and governance are the processes and policies required to ensure the availability, usability, integrity, and security of an organization’s data. They provide a framework for managing data assets and helping to maintain data quality. It focuses on data governance and metadata management, data security, master data management, information lifecycle management, data archiving, and the management of unstructured data. We are able to use AWS Data Catalog, Azure Purview, and GCP Data Catalog with the leading cloud providers. We can use Apache Atlas as an open-source platform for data management and governance for a cloud-agnostic platform.
In the case of DevOps, we can use services provided by AWS, Azure, and GCP like AWS CodeBuild, AWS CodeDeploy, Azure DevOps, and GCP Cloud Build. All these services integrate or offer GIT as a repository. CI/CD processes we can build based on Jenkins or use cloud-native services. The infrastructure can be managed and built using Terraform that supports all mentioned platforms, but there are differences in code implementation for different providers. Nevertheless, in case of migration, we have the possibility to work with the same tool.
Data visualization
Most of the tools offered by leading cloud providers are able to connect to the most popular data sources. In this case, we can use Power BI with Redshift and Data Studio with other sources. There are also visualization tools offered by other providers: Tableau, Qlik, IBM Cognos, or open-source. In the case of visualization, we have huge differences in functionality, pricing, and licensing. Cloud Providers offer these tools as a service, but you can also install them on your local machine.
Summary
As customers begin to consider the cloud as a place for their upcoming data platform, leading cloud providers offer an adaptation program, free trial accounts and migration support.
As the journey starts, a clearly defined Minimum Viable Product (MVP) project should serve you as an entry point. At Devapo, we can help you create cloud based data platform. Our MVP will present business value by solving customer use cases and needed outcomes. As the platform matures, we can begin to deploy advanced analytical ML and AI workloads to automate processes and begin to predict and forecast.
Many cloud providers offer compatible services and tools that enable the foundation for data cloud platforms. Becoming a data-driven organization in the cloud is a step that requires the involvement of various stakeholders and investment. Hopefully, with what you’ve read, it will be easier to understand how to develop a cloud agnostic data platform.
Dou you want to be data-driven organization?
We can help you leverage the potential of both Cloud and Data



