


- Krystian Bajun
- Read in 5 min.
What is Kafka? What is Kafka used for? How does it work?
Let me answer these and many other questions in this article. Here you can find all information that you need to know to understand Kafka.
The beginnings of Apache Kafka
Kafkas are related to LinkedIn, where the project started. The team’s idea was to create an operating system, that could handle an enormous set of messages processed in real time, additionally embedded in a scattered structure, what actually had been very challenging. This all made us give up the idea of traditional, monolithic solution. In effect, we invented a tool, which main features were high computing capacity, enabling a dynamic processing of significant amounts of data. The application was able to manage processing up to 35 millions of messages per second while reading and 7 millions messages while recording.
What is Apache Kafka?
Apache Kafka is a platform which can be used for stream transferring of events, which are called ’message brokers’. This kind of apps enables sending and receiving messages between two or more of clients’ apps. They consist of interfaces responsible for validation, reception and convertion of those messages among targeted group of recipients. They enable flexible communication between scattered information operating systems. The producer can send messages to Kafka cluster, whereas theconsumer downloads messages from the stream generated by Kafka.
Distinctive features:
Speed
The distinctive feature of is its effectiveness and velocity. It can easily process enormous amounts of data in the stream. With proper server configuration it can have the capacity of even 100 000 messages per second. Another advantage is no data loss.
Security
Kafka’s big advantage is certainly its security, resulting from the replication mechanism. With proper configuration messages in topic are replicated, that is copied and stored in cluster, so as to prevent data loss.
Versatility
There are many methods of plugging the app and using Kafka.
Reliability
Another strength is its reliability. Kafka is a scalable tool, messages are demerged and saved in partitions. That’s why Kafka is highly resistible to damages.
Scalability
Kafka is characterized by scalability. It was designed, so that the cluster can be used as a central system for message sending, with centralizing the communication between different data systems. In case of failure Kafka will immediately and automatically enable the data retrieval.
Terminology
Kafka’s broker is a single instance of Apache Kafka, i.e a server.
Kafka’s cluster can consist of many independent servers, that is brokers connected to each other.
The producer is used to produce messages. The producers are processes implementing records to topics in Kafka’s broker. The producers send data to those topics. They don’t wait for the broker’s confirmation and send messages as quick as possible. In case of clusters enlargement by one broker’s instance, all the producers automatically detect change and send messages to the new broker.
The consumer – downloads messages from Kafka’s topics. It sends asynchronous download demand to broker.
It is possible to have a single Kafka broker, but it doesn’t provide all the benefits, that are available.
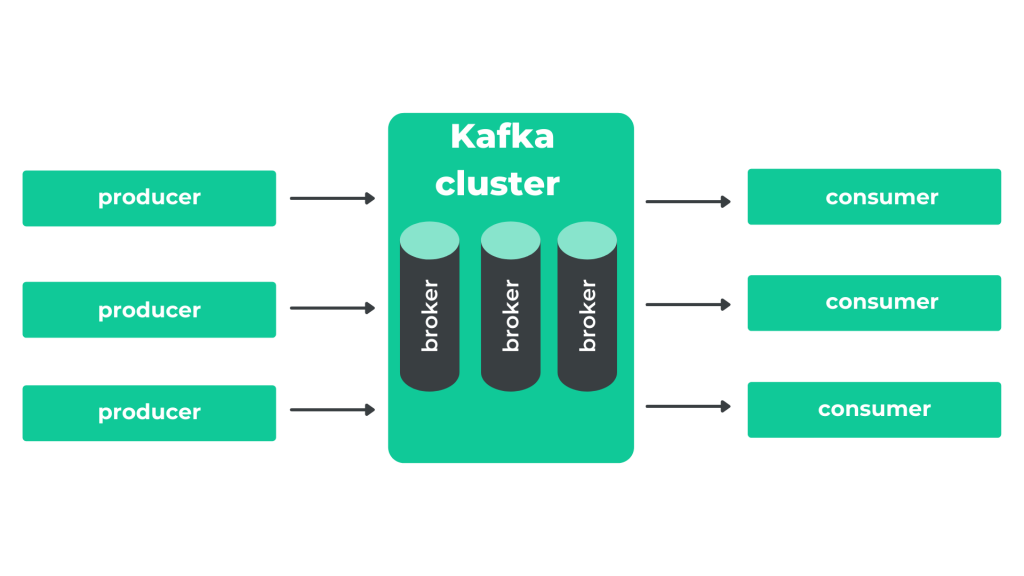
Kafka Cluster
The producer as well as the consumer is linked only to one topic. The sender transfers the message from specific topic and the receiver gets all of the messages from the assigned topic. Kafka guarantees that every message sent within one topic, will be received by every other recipient, who follows this very topic. The messages can come from many senders.
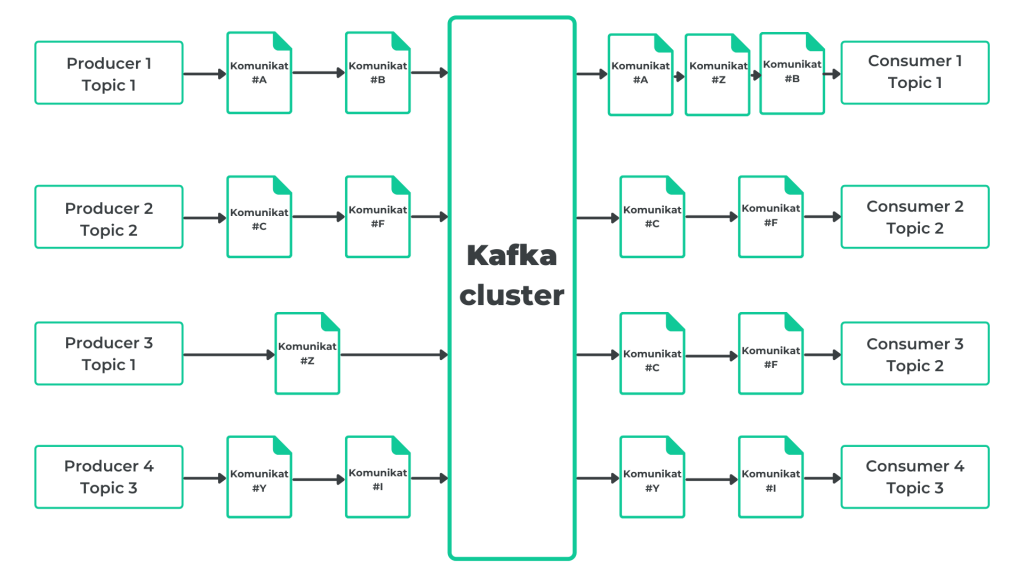
On the presented diagram we can see a configuration of Kafka’s cluster made out of three topics, 4 producers and 4 consumers. Let’s discuss this connection within a topic, each separately. Producer 1 and Producer 2 is assigned to the topic 1. We can observe that 3 messages have been sent (A,B,Z). The first of them has been sent by the Producer 1, followed by Producer 3 and then again by the Producer 1. On the other hand, messages are followed and received by only one Consumer. Messages will arrive then in the following order (A,Z,B).
The opposite scenario in Topic 1. Here we have one Producer 2 and two Consumers (2 and 3). Both messages (C,F) will be simultaneously received by them.
In Topic 3, the Producer 4 sends two messages (Y,I) which are followed by the Consumer 4.
Partitions
In order to achieve the highest efficiency, topics in Kafka are demerged into partitions, and every message sent by the producer is demerged as well. For instance the producer sends a message, which will be demerged into 4 parts, each of them will be allocated adequately on each partition and linked to broker. With a proper internet and server configuration there are chances for 4 time higher bandwidth.
Replication
To secure data in case of failure Kafka enables replication mechanism. It consists in copying the partition and storing data in many servers. Each partition can have only one server, called the leader. It means that it is responsible for reading and saving of the given partition. There is an option of setting the coefficient of replication during the configuration process. Let’s assume it is set to 4. In reality it means that there will be only one leader and three brokers which will only copy data to the remaining partitions.
In conclusion, replication is used to increase security and to protect the data in case of failure. The leader mirrors the current state of data and replications are only its copies.
Offset
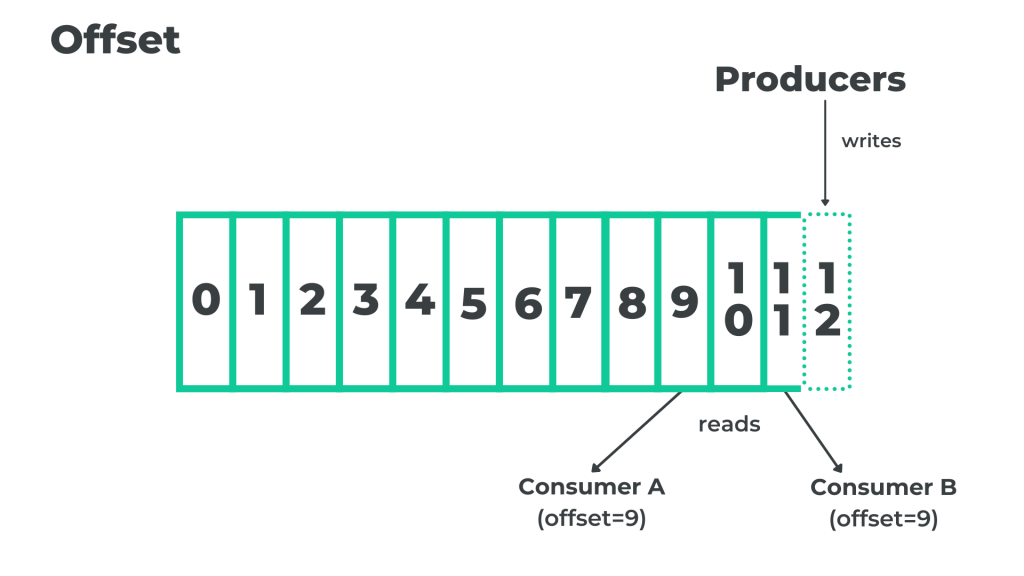
By the notion ’offset’ it is meant that Kafka offers a method to appoint the order of receiving the messages by Kafka’s topics. It is a process of sending and reading the message. Referring to the above illustration, we can see a queue including 12 messages. By sending a new message to the queue, the Producer will give it a new offset with an identifier number 13. The Consumer reads the whole message from bottom to top. Wanting to read the last one – the 13th – he needs to get through all of the 12 previous ones. Similarly, if they want to read the message with an offset 3, first they’ll have to read messages with identifiers of 0,1,2 and then with number 3.
Guarantees
In order to ensure security in Kafka, we can refer to guarantees. What is meant by that? In a scattered system, a guarantee is important. Whenever a failure occurs, the environment will be able to continue to work steadily and efficiently, even if part of the servers stops working. This is guaranteed by the system of replications, which was described previously.
Additionally, messages in Kafka are demerged into 3 groups (at most once, at least once, exactly once)
- exactly once – means that a message will be delivered to the consumer only once,
- at most once – means that a message may be lost, but Kafka guarantees, that it won’t be delivered again,
- at least once – opposite to at most once, a message will never be lost, but can be duplicated
Without proper configuration Kafka guarantees the delivery of message at least once. To change the default setting, a proper implementation is required. As a consequence, it may reduce its efficiency.
Summary
Above you could find all the information you need to know to understand Kafka at a basic level.
In the next article, I will present the basic configuration of Apache Kafka on a Docker container and a microservice built in the Spring Boot framework.



