


- Mariusz Kujawski
- Read in 4 min.
Here, I presented how to query a Data Lake using Azure Synapse Serverless Pool and the Lake database. Azure Synapse workspace enables us to create a SQL Database on top of a Data Lake, but this isn’t managed by Spark. In this type of database, we can only use a serverless SQL pool.
In this follow-up to the previous article, I’ll show you how to query data in a Synapse serverless SQL pool using SQL database.
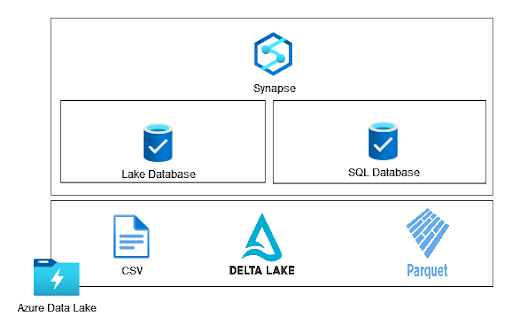
What is possible with SQL Database?
- Create external tables
- Create views
- Create stored procedures
- Use OPENROWSET command to query files
In a nutshell, we can create a logical data warehouse with a serverless pool on top of a Data Lake. This allows any tool to work with files in a Data Lake like with SQL tables. Once we create our data model, we can use a SQL client, Power BI, SQL Management Studio, Python, etc. to query files in the Data Lake.
How to query data in Synapse SQL pool
The simplest way to query data in a Data Lake in Azure is to use the OPENROWSET command. As it’s presented below you can query parquet files from the files kept in the Azure Data Lake container.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://xxx.dfs.core.windows.net/silver/movies/netflix/',
FORMAT = 'PARQUET'
) AS [result]Using Synapse workspace GUI you can navigate to the specific location and select a file that you want to display.
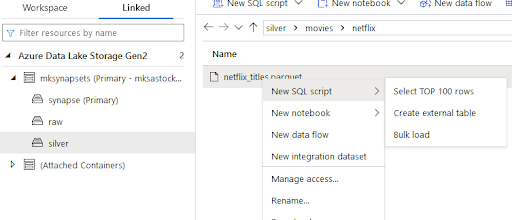
However, this method requires your knowledge of the files that you keep in the Data Lake. To avoid navigating through directories every time you want to query data, you can create a query-based view or tables.
CREATE VIEW vnetflix
AS
SELECT
*
FROM
OPENROWSET(
BULK 'https://xxx.dfs.core.windows.net/silver/movies/netflix/netflix_titles.parquet',
FORMAT = 'PARQUET'
) AS [result]After executing the query you should see a new view in the Synapse workspace in the SQL database tab. As you can see, columns are the varchar data type. It’s not perfectly accurate, but we can query data using the view name. We can set appropriate data types using the WITH command.
WITH (
vendorID varchar(4),
tpepPickupDateTime datetime2,
passengerCount int
) AS result;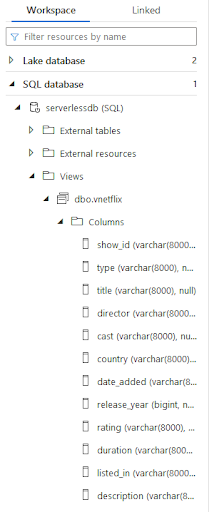
Another option in SQL database is to create an external table where we can define source files’ location and data types. To perform mathematical operations and improve query performance, data types are important.
For instance, according to Microsoft’s recommendation integer-base data types perform better in SORT, JOINs, and GROUP BY. To create an external table you need to set up a data source and a format file like in the code below.
CREATE EXTERNAL DATA SOURCE silver WITH (
LOCATION = 'https://xxx.dfs.core.windows.net/silver'
);
CREATE EXTERNAL FILE FORMAT ParquetFormat
WITH (
FORMAT_TYPE = PARQUET
);
CREATE EXTERNAL TABLE netflix (show_id VARCHAR(256),
type VARCHAR(256),
title VARCHAR(256),
director VARCHAR(256),
cast VARCHAR(256),
country VARCHAR(256),
date_added DATE,
release_year BIGINT,
rating DECIMAL(10,2),
duration VARCHAR(256),
listed_in VARCHAR(256),
description VARCHAR(256))
WITH (
LOCATION = 'movies/netflix',
DATA_SOURCE = silver,
FILE_FORMAT = ParquetFormat
);Created tables can be seen in Synapse workspace, as shown in the screen below.
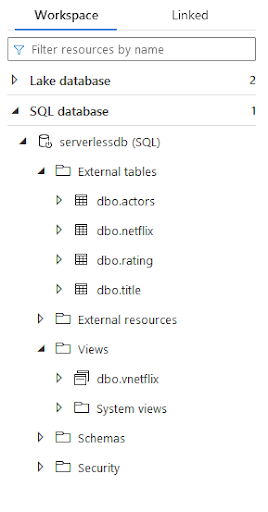
As presented, Synapse allows us to create a logical data model based on files stored in the Data Lake. We can use tables to import data into Power BI, ad-hoc analysis, or python scripts.
When you need low latency, such as Power BI direct queries, you should avoid using Synapse Serverless.
File formats
Synapse serverless supports popular data formats like Parquet, Delta Lake, and CSV. Essentially, the Delta format stores data as parquet, but has additional features that provide transaction logs and more flexibility when it comes to editing the content. This includes updating, deleting, and merging. It’s more effective to use Paquet compared to CSV files because Parquet has columnar compression, we can query only a subset of columns, and keeps metadata information.
To see the main differences between Parquet and CSV I’ll execute two queries.

SELECT
count(*)
FROM
csv_netflixTotal size of data scanned is 4 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
SELECT
count(*)
FROM
parquet_netflixTotal size of data scanned is 1 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
You can see that the SQL engine needs to scan the entire CSV file and only metadata information from the parquet file. This behavior is significant from a cost perspective, we pay for processed data in Synapse Serverless.
SQL Stored procedures
The last issue is how to automate table creation and schema inference. For a table with a few columns, it’s not a big deal, but for a large number of tables, it will take a lot of time. To avoid manual work I created a python script that reads metadata from parquet files and creates table definitions based on it.
def read_metdata(file, abfs):
print(f"-----------------{file}")
pfile = pq.read_table(file, filesystem=abfs)
columns = []
for x in pfile.schema:
columns.append(f"{x.name} {convert_to_sql(x.type)}")
tab_name = file[:file.find(".")].split("/")[-2]
location = "/".join(file.split("/")[1:-1])
sql = ""
sql = f"CREATE EXTERNAL TABLE {tab_name} ("
sql += ",\n".join(columns)
sql += f""")
WITH (
LOCATION = '{location}',
DATA_SOURCE = silver,
FILE_FORMAT = ParquetFormat
);"""
return sqlThe code traverses folders in Data Lake, reads metadata and names parent folders that act as table names. You can find all the code in my git repository.
https://github.com/MariuszKu/azure_codes
Summary
Using SQL databases in Synapse Serverless pools is a good option if you aren’t planning to implement Spark pools. You can load your files to your Data Lake via Azure Data Factory, Azure Synapse integration pipelines, third-party ETL tools, or python scripts and then create a metadata layer on the top of your Data Lake and use SQL-endpoint to query your data.
Check out other articles related to data engineering
Discover tips on how to make better use of technology in projects



