




- Karol Sobota
- Read in 8 min.
One of the most popular components of the Spring library, which significantly improves the development of modern applications, is Spring Data JPA. The main idea behind this component is to streamline the way basic queries are created on the database. Thus reducing repetitive code (boilerplate). However, we must bear in mind that the queries generated by this tool are sometimes not optimal. This can lead to performance problems.
To address these issues, in version 2.1 of the Spring Data JPA component, the Entity Graph mechanism was introduced. This mechanism allows you to more precisely manage which information should be retrieved from the database, depending on the current demand in the application.
In this article, we’ll show you how to use the Entity Graph tool. You will also learn about situations in which you should leverage it.
JPA FetchType
To understand the principle of the Entity Graph tool, we need to familiarize ourselves with the types of fetch plans that are available in the JPA component: FetchType.LAZY and FetchType.EAGER.
These plans, are set within the fetch annotation parameter: @Basic, @OneToOne, @OneToMany, @ManyToOne and @ManyToMany.
Each of these, has a default value for this parameter. By changing this value, we affect the number of relations fetched from the available accessible data.
The following figure shows a diagram of two entities that represent customer and shopping cart data in an online store.

The definitions of these entities using the Spring Data JPA component look as follows:
@Entity
public class Client {
@Id
@GeneratedValue
private UUID id;
@NotNull
private String firstname;
@NotNull
private String lastname;
@OneToOne
@JoinColumn(name = "cart_id")
private Cart cart;
}
@Entity
public class Cart {
@Id
@GeneratedValue
private UUID id;
@NotNull
private Double value;
@OneToOne
private Client client;
}
These entities are related to each other by a bidirectional one-to-one relationship. Let’s see how setting a given download plan in this relationship, affects the amount of data downloaded. To do this, call a method that retrieves client data, after setting the fetch parameter in the @OneToOne annotation in the Client.java class:
clientRepository.findById(id);
The SQL queries generated after calling this method, depending on the fetch plan set, look as follows:
@OneToOne(fetch = FetchType.EAGER)
select client0_.id as id1_1_0_, client0_.cart_id as cart_id4_1_0_, client0_.firstname as firstnam2_1_0_, client0_.lastname as lastname3_1_0_, cart1_.id as id1_0_1_, cart1_.value as value2_0_1_ from client client0_ left outer join cart cart1_ on client0_.cart_id = cart1_.id where client0_.id = ?
@OneToOne(fetch = FetchType.LAZY)
select client0_.id as id1_1_0_, client0_.cart_id as cart_id4_1_0_, client0_.firstname as firstnam2_1_0_, client0_.lastname as lastname3_1_0_ from client client0_ where client0_.id = ?
As we can see from the log snippets above, in the case where the FetchType.LAZY plan was set, only the customer data was pulled. In case we set the FetchType.EAGER plan, we have pulled the data from the shopping cart additionally.
Since in this case only the customer’s data was of interest, any behavior we obtained after setting FetchType.EAGER is not the desired one. As we can guess, the problem would be much more noticeable if the Client entity contained not one, but more than a dozen relationships with a “greedy” fetch plan set.
In such a case, calling a method that retrieves Client data would result in retrieving a lot of redundant information that we did not plan to use. On the other hand, what if we want to fetch both customer and shopping cart data, and we set the FetchType.LAZY plan in the relationship? Let’s check this by replacing the previously called method with:
clientRepository.findById(id).get().getCart().getValue();
The generated SQL query is then as follows:
select client0_.id as id1_1_0_, client0_.cart_id as cart_id4_1_0_, client0_.firstname as firstnam2_1_0_, client0_.lastname as lastname3_1_0_ from client client0_ where client0_.id = ? select cart0_.id as id1_0_0_, cart0_.value as value2_0_0_, client1_.id as id1_1_1_, client1_.cart_id as cart_id4_1_1_, client1_.firstname as firstnam2_1_1_, client1_.lastname as lastname3_1_1_ from cart cart0_ left outer join client client1_ on cart0_.id = client1_.cart_id where cart0_.id = ?
This time two SQL queries were called, which is also not the desired behavior. We can conclude that depending on what information we plan to use, we need to set up different download plans in different situations. We hit a problem here, because the configuration of download plans is static. It cannot be changed during the operation of the application. This brings us to the main premise of the Entity Graph tool, which is the ability to dynamically determine how to retrieve data available within related entities.
Graph Implementation
This tool is available within the spring-boot-starter-data-jpa component, so in order to use it, we need to include the following entry in the pom.xml file.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
One way to define a graph is to add the @NamedEntityGraph annotation over the entity of the class whose object we will be retrieving. This annotation, has an attributeNodes parameter. Using the @NamedAttributeNode annotation, we can define the fields we want to include when retrieving data.
Below is an example of a simple graph, defined for the Client.java class.
@NamedEntityGraph(
name = "client-entity-graph",
attributeNodes = {
@NamedAttributeNode("cart")
}
)Subgraph Implementation
Since dependent entities, can have relationships to other entities, graph definitions are usually more elaborate. To put this into practice, let’s extend our existing Cart entity model to include a relationship to the Item class, which represents the item in the shopping cart.
After the extension, the entity diagram is as follows:
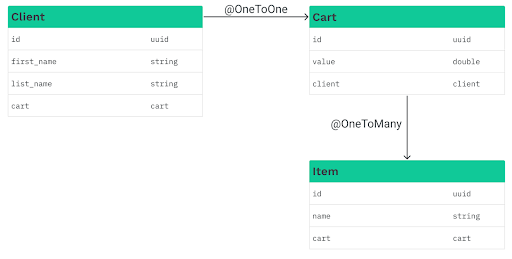
The definition of the Item entity is as follows:
@Entity
public class Item {
@Id
@GeneratedValue
private UUID id;
@NotNull
private String name;
@ManyToOne
@JoinColumn(name = "cart_id")
private Cart cart;
}And a relationship to that entity, in the Cart.java class:
@OneToMany(mappedBy = "cart") private List<Item> items = new ArrayList<>();
In the graph presented so far, the behavior specified is to retrieve the shopping cart data along with the customer data. However, after modifying the entity, each shopping cart contains a list of items. Depending on the situation, we may need different data sets. To specify whether we want to always retrieve data for the items in the shopping cart, we need to use the @NamedSubgraph annotation. We set it within the subgraphs parameter of the @NamedEntityGraph annotation. Let’s look at the following example:
@NamedEntityGraph(
name = "client-with-light-cart-entity-graph",
attributeNodes = {
@NamedAttributeNode(value = "cart", subgraph = "items-subgraph")
},
subgraphs = {
@NamedSubgraph(
name = "items-subgraph",
attributeNodes = {
@NamedAttributeNode("client")
}
)
}
)We can see that the definition of a subgraph is very similar to the definition of the graph itself. The only difference is in the placement of the definition.
This is because the subgraph so defined is used within the subgraphs parameter of the @NamedAttributeNode annotation.
From the prepared graph, we can use it in two ways. The first, and simplest, is to override the method in the repository interface. It will retrieve the data, and then mark it with the @EntityGraph annotation, within which the name of the graph we want to use will be specified.
An example of a modified method in the repository of the Client class is:
@EntityGraph("client-with-light-cart-entity-graph")
@Transactional
Optional findById(@NotNull UUID id);The generated SQL query after calling this method is as follows:
select client0_.id as id1_1_0_, client0_.cart_id as cart_id4_1_0_, client0_.firstname as firstnam2_1_0_, client0_.lastname as lastname3_1_0_, cart1_.id as id1_0_1_, cart1_.value as value2_0_1_ from client client0_ left outer join cart cart1_ on client0_.cart_id = cart1_.id where client0_.id = ?
This time, one query was executed. We were able to retrieve customer and cart data, but without information about the items inside the cart. To change this, let’s make one more modification to our graph. Add the “items” parameter to the list of items to be retrieved.
@NamedEntityGraph(
name = "client-with-detailed-cart-entity-graph",
attributeNodes = {
@NamedAttributeNode(value = "cart", subgraph = "items-subgraph")
},
subgraphs = {
@NamedSubgraph(
name = "items-subgraph",
attributeNodes = {
@NamedAttributeNode("client"),
@NamedAttributeNode("items")
}
)
}
)After this modification, calling the previously rearranged method again will generate the following query:
select client0_.id as id1_1_0_, client0_.cart_id as cart_id4_1_0_, client0_.firstname as firstnam2_1_0_, client0_.lastname as lastname3_1_0_, cart1_.id as id1_0_1_, cart1_.value as value2_0_1_, items2_.cart_id as cart_id3_2_2_, items2_.id as id1_2_2_, items2_.id as id1_2_3_, items2_.cart_id as cart_id3_2_3_, items2_.name as name2_2_3_ from client client0_ left outer join cart cart1_ on client0_.cart_id = cart1_.id left outer join item items2_ on cart1_.id = items2_.cart_id where client0_.id = ?
As expected, we received the customer’s data and shopping cart, but this time with information about all the items in it, in just a single request.
Multiple graphs for a single entity
Since we need a different set of data depending on the demand, there will often be a need to create several graphs for a single entity. See how to add the two versions of the charts we discussed earlier (with basic and full shopping cart data) to the Customer entity. For simplicity, we omitted the attribute list:
@NamedEntityGraphs({
@NamedEntityGraph(
name = "client-with-light-cart-entity-graph",
attributeNodes = {...}
),
@NamedEntityGraph(
name = "client-with-detailed-cart-entity-graph",
attributeNodes = {...}
)
})In a situation where we have two graphs defined, we need two methods to retrieve data at the same time. Therefore, we will be able to tag with the @EntityGraph annotation.
We can use the name with the schema find + custom name + By + parameter name. This will help us to define several methods, used to be tagged by different graph definitions for the same entity. An example of a method definition looks as follows:
@EntityGraph("client-with-light-cart-entity-graph")
@Transactional
Optional findWithLightCartById(@NotNull UUID id);
@EntityGraph("client-with-detailed-cart-entity-graph")
@Transactional
Optional findWithDetailedCartById(@NotNull UUID id);EntityManager in conjunction with EntityGraph
The second way, which allows you to create a graph and then use it when retrieving data from the database, is to use the EntityManager class.
The definition of the previously presented graph for the Client class using this tool is as follows:
EntityGraph entityGraph = entityManager.createEntityGraph(Client.class);
entityGraph.addSubgraph(“cart”).addAttributeNodes(“client”, “items”);
Using the graph prepared this way then comes down to calling the following method:
entityManager.find(Client.class, id,
Collections.singletonMap(GraphSemantic.FETCH.getJpaHintName(), entityGraph));
Summary
As part of the article, the EntityGraph tool was presented along with a sample implementation. In addition, JPA fetch plans are discussed, and how setting a particular plan affects the generation of SQL queries.
In our opinion, the tool allows you to optimize the generated queries in an easy way. It maintaining a small amount of redundant code that can occur when writing native SQL queries.
Check out other articles in the technology bites category
Discover tips on how to make better use of technology in projects



