




- Mariusz Kujawski
- Read in 6 min.
Using Databricks, you can build a powerful and scalable platform for advanced analytics purposes. In this article, I will show how to integrate and use Databricks on GCP – Google Cloud Platform.
About Databricks
Databricks is a cloud-based big data analytics platform used to create Data Lakes or Data Lakehouses. The solution implements its own platform, based on the open-source Apache Spark, and can be integrated with Azure, AWS and GCP. The platform enables users to create and orchestrate complex data analytics pipelines and collaborate more effectively. It allows customers to quickly set up a secure cloud environment for processing, analyzing and visualizing big data. Databricks also provides a range of advanced machine learning and deep learning capabilities.
Databricks supports languages such as SQL, Python and Scala. In addition, it uses notebooks to edit and create code as well as allows users to visualize data. Databricks provides integration with Git repositories. With this tool, you can use Lakehouse architecture. It allows you to use the metadata layer to analyze and modify files in the Data Lake. Databricks supports many big data formats, such as Parquet, AVRO, JSON, CSV, GZIP and Delta format. What’s interesting about the Delta format is the ability to modify data, and the ability to analyze “time travel” data at any moment.
Databricks Infrastructure GCP vs. Azure
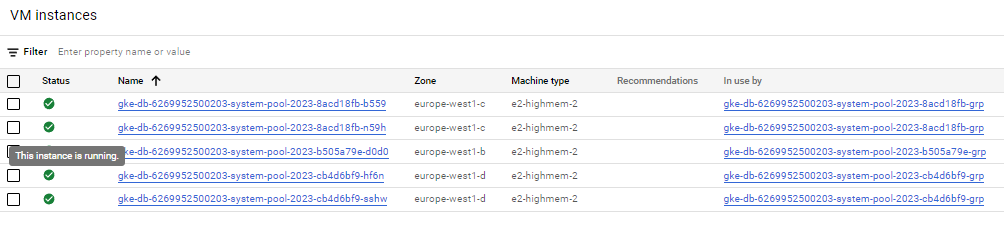
When we set up a Databricks workspace in our account, it creates an infrastructure for our workspace and cluster. Below, you can see how it looks in Azure and GCP. In the case of GCP the workspace will be deployed on Google Kubernetes Engine(GKE). I think this is one of the most important points to understand Databricks costs. The GCP allows us to create the workspace using Marketplace.
Databricks on GCP Kubernetes

Databricks on Azure
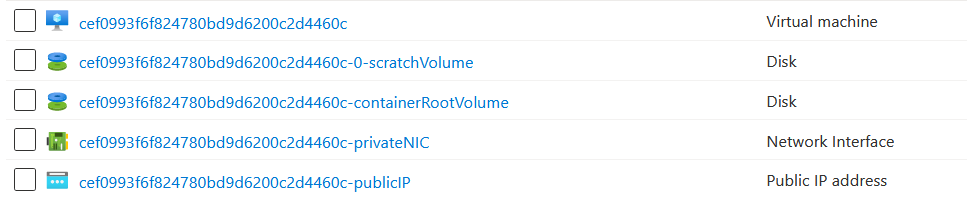
How to read data from the Azure vs. GCP storage
Important advantage of Databricks is separation between compute and storage. This architecture helps us to integrate our analytical platform with different cloud providers. Below you can see the same file on Azure Storage Account and GCP Cloud Storage.


Since Databricks is built on Apache Spark we can use spark commands to read, transform and write data. I’ll show how we can read files in Azure. In the next paragraph I’ll demonstrate the same activity for GCP.
Databricks on Azure
Here you can see a really simple example that reads data from a compressed CSV file to spark DataFrame.
df = spark.read.option("header",
"true").option("delimiter","\t").csv("abfss://data@xxx.dfs.core.windows.net/raw_title_basics.tsv.gz")To display data we can use the code below.
display(df.limit(10))
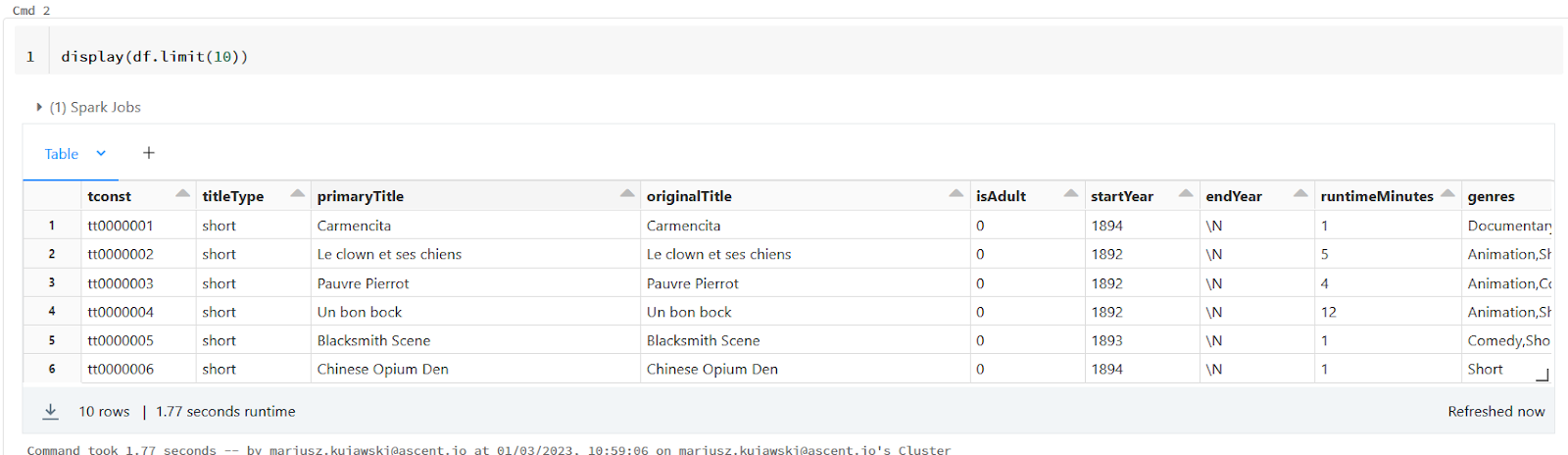
Spark DataFrame allows us to modify data, clean or transform it, and finally save it to Data Lake. Also, in addition to saving files, we can register a new table in our Hive metastore and use that name to query the data in SQL or Spark.
df.write \
.option("path",""abfss://data@xxx.dfs.core.windows.net/dwh/moviews") \
.option("format","parquet") \
.mode("overwrite") \
.saveAsTable("dwh.movies")Databricks on GCP
Let’s do the same exercise in GCP. I’ll skip the details of creating a workspace and cluster. I’ll just note that you can create a workspace and cluster using the GCP marketplace. A free version of Databricks can be subscribed to for 14 days.
The process of creating the cluster is almost the same as in Azure. Here you can find instructions on how to do it.
If your Databricks cluster is up and running, we can create a notebook, paste the code below and execute it. As you see, the code is exactly the same as in Azure. The difference is only in the location of the file.
df = spark.read.option("header", "true").option("delimiter","\t").csv("gs://testsource/raw/raw_title_basics.tsv.gz")
df.write \
.option("path","gs://testsource/dwh/moviews") \
.option("format","parquet") \
.mode("overwrite") \
.saveAsTable("dwh.movies")If you execute the code you should see new files in your storage.
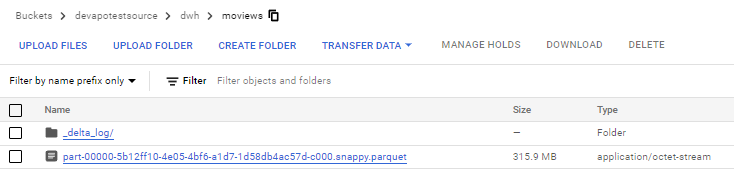

Datbricks on GCP – Integration
From the perspective of the data engineering team, Databricks appears to be fully integrated with GCP. We can use it with Cloud Storage, BigQuery, Pob/Sub, Looker. We can leverage Databricks as our ETL tool, to process and transform data and serve data, using SQL, or use BigQuery as a Data Warehouse. The presented architecture allows us to divide its use between engineering, data science and BI teams.
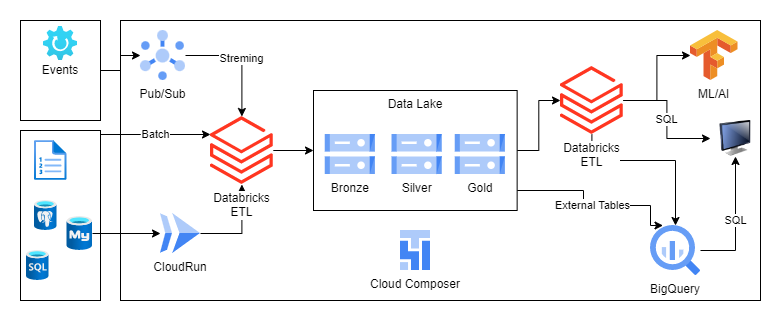
BigQuery and Databricks Integration
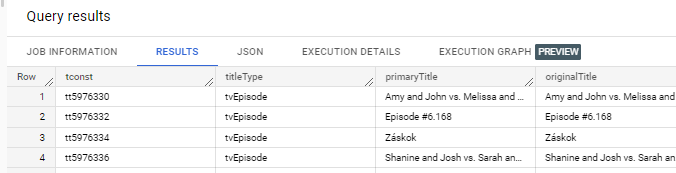
BigQuery in GCP is a very powerful platform for storing and querying data using SQL. This SQL engine has very good performance and is not expensive. Based on my integration tests with Databricks, I realized that we can easily use the files generated from Databricks in BigQuery using External tables. External table is one of the features provided by BigQuery that allows us to read data directly from our cloud storage/data lake. The code below demonstrates how to create a table and query it in BigQuery.
CREATE EXTERNAL TABLE test.movies_dwh OPTIONS ( uris = ['gs://testsource/dwh/moviews/*.parquet'], format = 'PARQUET'); SELECT * FROM `test.movies_dwh` LIMIT 1000
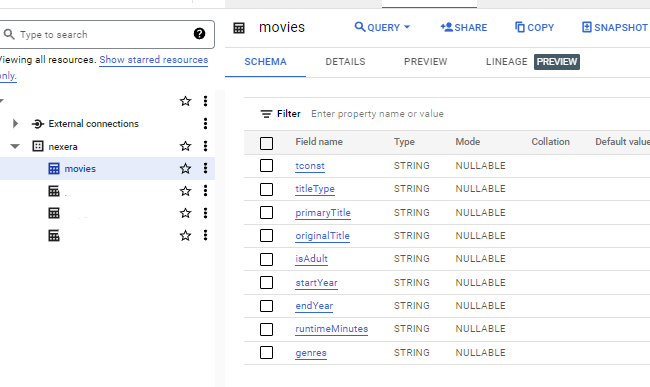
The newly created table should be visible in the BigQuery workspace as shown in the following screenshot.
Another option to integrate Databricks and BigQuery is to store data in BigQuery or read from there. Below I’m presenting how we can save data in a BigQuery table or read it from the public dataset offered by GCP.
Saving data in BigQuery.
df.write \
.format("bigquery") \
.option("temporaryGcsBucket", "mk12345") \
.mode("overwrite") \
.option("table", "test.movies") \
.option("project", "dev-test") \
.save()Reading data from the public dataset.
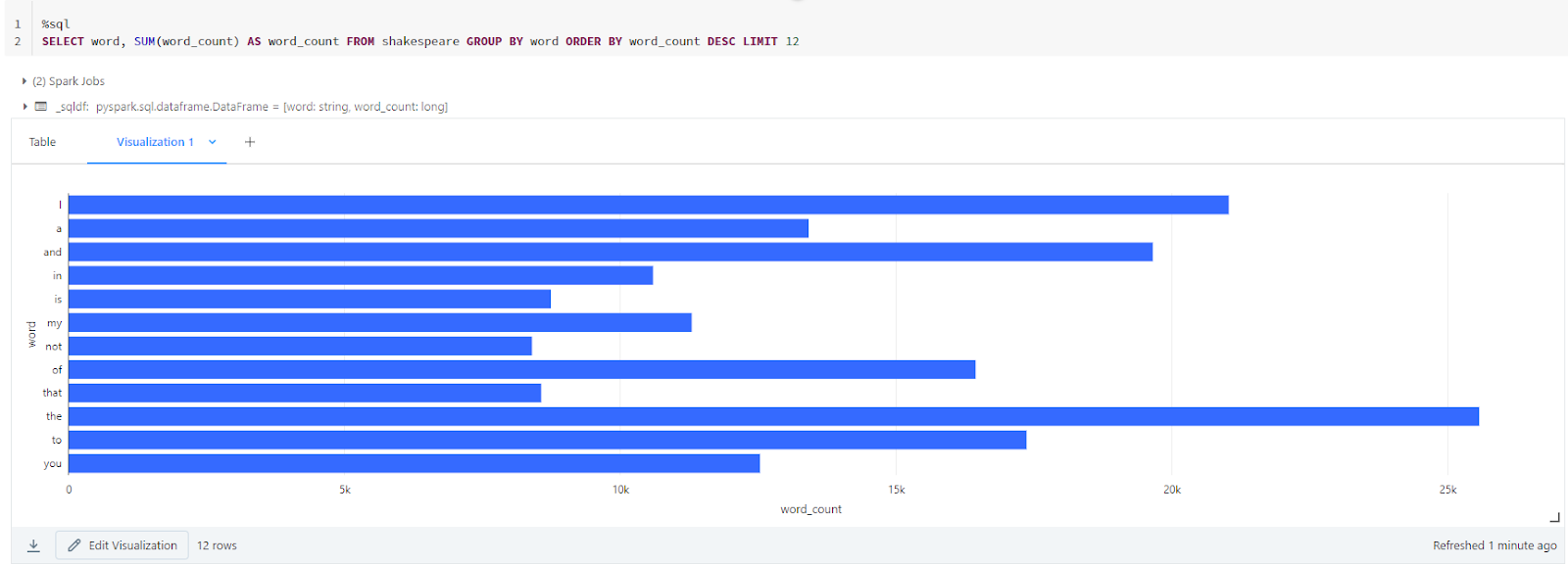
table = "bigquery-public-data.samples.shakespeare"
df = spark.read.format("bigquery").option("table",table).load()
df.createOrReplaceTempView("shakespeare")An example of Data Visualization in Databricks notebook.
Delta format and data modification
BigQuery at the time of writing this article does not support delta format, but we can use it with Databricks. What is it? Delta is a data format based on Apache Parquet. It is an open source project. Delta is like Parquet, a column-oriented format, but with transaction log files and as a result provides ACID transactions and a level of isolation for Spark.
Delta format provides a few powerful features like:
- Time travel
- Delta cache
- Transactions support
- Merge
- Better data organization
- Schema evolution
We can create a delta table very simply in spark, we need to change our data format in the write command.
df.write \
.option("path","gs://testsource/dwh/moviews_dale") \
.option("format","delta") \
.mode("overwrite") \
.saveAsTable("dwh.movies_delta") As a result of the command the new table will be created in the metadata Hive store and files appear in the cloud storage. You can notice here that we have a few files and _delta_log catalog where the transaction log will be stored.
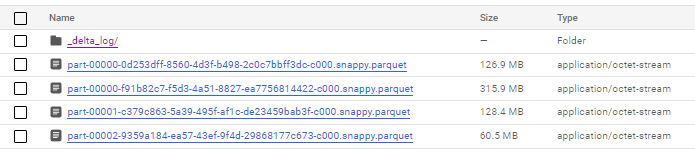
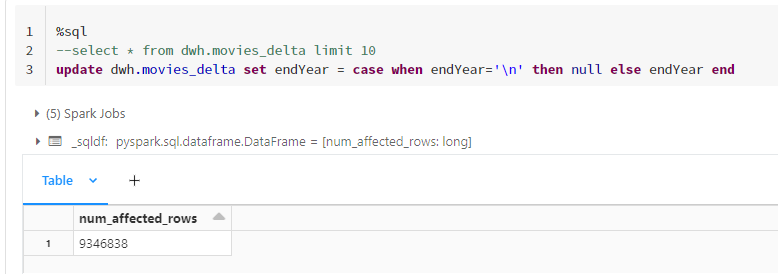
Delta format delivers to us a new functionality in the big data world-data modification. Below I presented how we can update our table using SQL in Databricks.
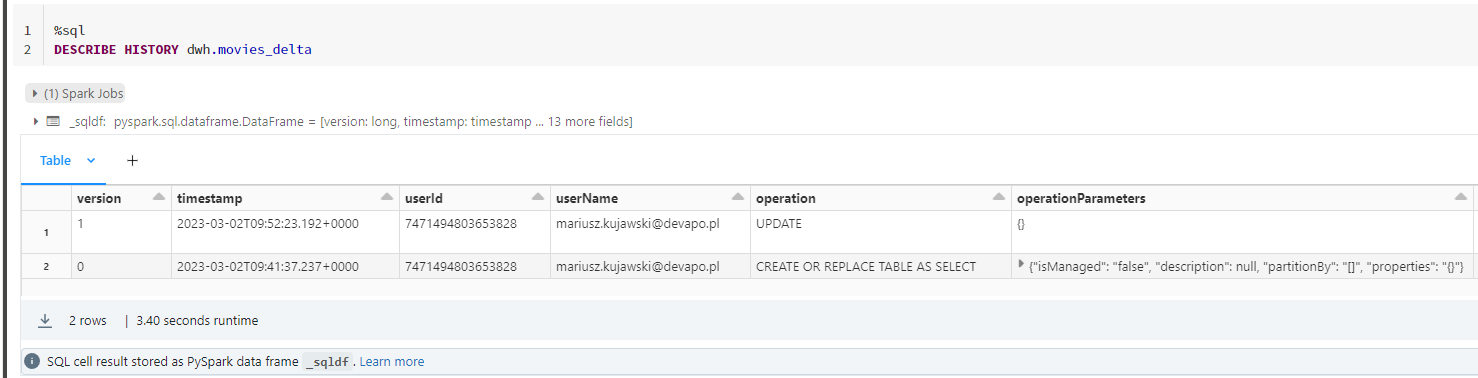
DESCRIBE HISTORY dwh.movies_delta
Summary
Databricks supports many different programming languages like Python, Scala, SQL. The advantage of this platform is its cloud-agnostic architecture. It gives the ability to easily migrate to another cloud provider without the need for expensive modification of the existing solution.
You could relatively easily migrate codes and data to another solution based on Apache Spark, such as AWS Glue, GCP Dataproc or Azure Synapse Spark Pool and Apache Spark cluster. It is worth mentioning that Databricks has features like Auto Loader or Live tables that are not supported by other Apache Spark based solutions.
Become a data-driven organization!
We help to leverage the potential of Cloud and Data



