


- Mariusz Kujawski
- Read in 8 min.
BigQuery is a serverless data warehouse, available in Google Cloud Platform, that enables users to explore large-scale data. GCP has a rich API with many methods and tools to load data. It supports data formats like AVRO, JSON, CSV, PARQUET, and OCR. We can load huge files with minimal effort using Python, GCP CLI tools, GCP console, or other programming languages.
In this post, you will be introduced to several methods showing how to load data into BigQuery. In the tutorial, I will use Python and the most popular data formats. I will also analyze performance of different file formats.
Introduction to file formats and datasets
My environment uses BigQuery as a database where I store my data. I plan to load the most popular formats: PARQUET, AVRO, JSON and CSV. We can apply different types of compression to these formats. I’ll test GZIP, SNAPPY, and BROTLI.
My dataset comes from IMDB. I converted the raw_title_basics.tsv file to AVRO, CSV, and PARQUET using Pandas and Python. Below you can see the size of files converted to various formats. My file has more than 9 mln records – it’s huge, but it is not BigData.
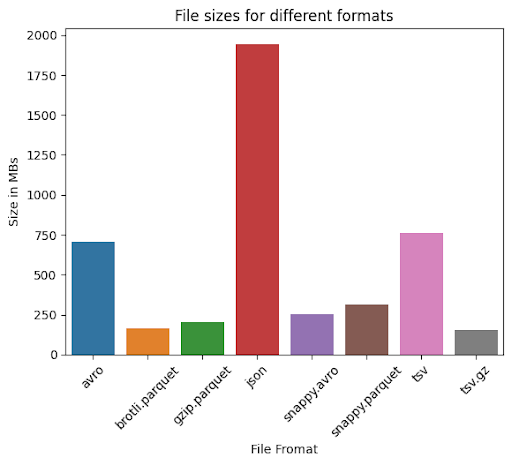
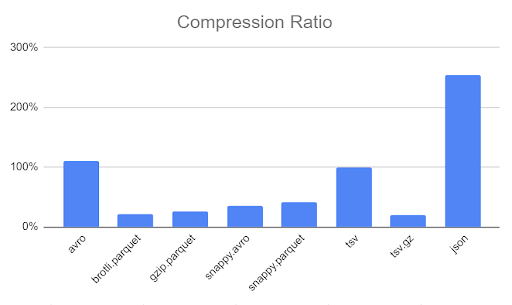
We can see from the chart above, that JSON takes two times more space than a TSV (CSV) file, whereas brotli.parquet takes only 22%. In the chart belowe, we can see the compression ratio achieved by my file.
Avro
Avro format is a row-based storage format – a binary file that stores schema in JSON. It allows schema evolution and is good for storing data from streaming. Avro format is easy to serialize by programing language (eg. currently C, C++, C#, Java, Python, and Ruby).
Parquet
Parquet format is a columnar format and keeps the schema of the file in the file header. When this format is used in conjunction with a columnar format, it is very effective at storing data compared to traditional row-oriented approaches.
CSV
The CSV format is the most common and traditional way to store data. It keeps information in rows separated by a defined separator.
Use code to convert data
To convert the file to a new format I use Pandas and fastavro libraries. Note, that Pandas doesn’t support the Avro format.
import pandas as pd
from fastavro import writer
schema = {
'doc': 'movies',
'name': 'movies',
'namespace': 'test',
'type': 'record',
'fields': [
{'name': 'tconst', 'type': 'string'},
{'name': 'titleType', 'type': 'string'},
{'name': 'primaryTitle', 'type': 'string'},
{'name': 'originalTitle', 'type': 'string'},
{'name': 'isAdult', 'type': 'string'},
{'name': 'startYear', 'type': 'string'},
{'name': 'endYear', 'type': 'string'},
{'name': 'runtimeMinutes', 'type': 'string'},
{'name': 'genres', 'type': 'string'}
],
}
def gen_data():
with open("/mnt/d/temp/data.tsv") as file:
file.readline()
while True:
line = file.readline()
values = line.split("\t")
if len(values) > 1:
yield {
'tconst' : values[0],
'titleType' : values[1],
'primaryTitle' : values[2],
'originalTitle' : values[3],
'isAdult' : values[4],
'startYear' : values[5],
'endYear' : values[6],
'runtimeMinutes' :values[7], 'genres' : values[8]
}
else:
break
path = "/mnt/d/temp/data"
df = pd.read_csv("/mnt/d/temp/data.tsv", sep="\t", low_memory=False)
df = df.astype(str)
df.to_parquet(f"{path}.gzip.parquet",
engine="pyarrow",
compression="gzip")
df.to_parquet(f"{path}.snappy.parquet",
engine="pyarrow",
compression="snappy")
df.to_parquet(f"{path}.brotli.parquet",
engine="pyarrow",
compression="brotli")
with open(f'{path}.snappy.avro', 'wb') as target:
writer(target, schema, gen_data(), codec="snappy")
with open(f'{path}.avro', 'wb') as target:
writer(target, schema, gen_data())
As it was illustrated in the chart “Compression Rate”, we have very good results in the case of Parquet format, AVRO snappy, but also CSV compressed by GZIP. If you use other files for this exercise you will observe that it depends on the file context. Parquet will be efficient in case of repeatable data in columns. A huge advantage of AVRO and Parquet vs. CSV is that we have file schema defined in the file herders.
Python methods to load data into BigQuery
This chapter will present a comparison between three methods that we can use in Python to load data in a fast way. More about it you can find in the documentation.
Method 1: Load data into BigQuery from GCP store
I will start by loading data into a BigQuery table from a GCP bucket. Let’s assume that a service or another application stores this data in your store bucket and now you need to load it into a table. You can achieve this using the “load_table_from_uri” method of the Python Client for BigQuery. The implementation is presented below.
def load_from_bucket(job_config, file):
start = time.time()
client = bigquery.Client()
name = file.replace(".","_")
job = client.load_table_from_uri(
f"gs://xxx/test_2/{file}",
f"xxx.test.{name}_2",
job_config=job_config,
)
job.result()
print(f"{name},{time.time() - start}")
return name, time.time() - start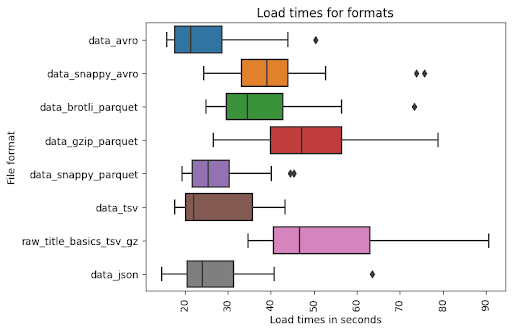
In this experiment, I loaded each file 20 times. As you can see, the most optimal performance was achieved using the Avro format without compression. According to GCP documentation, it’s the preferred format.
The next position is achieved by Parquet with snappy compression which is also described as a wise choice according to documentation.
Raw CSV and JSON without compression surprised me, but BigQuery can load uncompressed CSV and JSON files quickly because it reads them in parallel. Nevertheless, the size of the JSON file is huge compared to the origin file.
Method 2: Load a file from the local file system
In some circumstances, we need to load files from a local file system. To achieve this we can use our code, but we need to implement a new method load_dable_from_file. This method allows us to send data from our server, Docker container, etc. into BigQuery.
def load_local(job_config, file):
start = time.time()
client = bigquery.Client()
path = f"D:/temp/{file}"
name = file.replace(".","_")
with open(path, "rb") as source_file:
job = client.load_table_from_file(
source_file,
f"xxx.test.{name}",
job_config=job_config,
)
job.result()
print(f"{name},{time.time() - start}")
return name, time.time() - start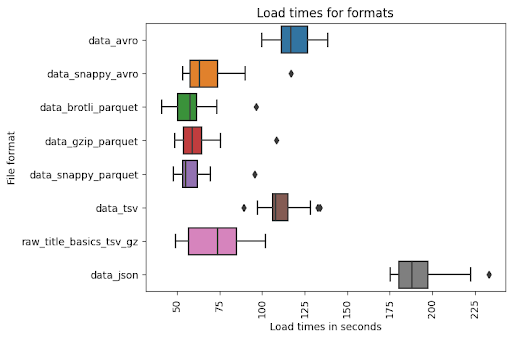
When I loaded the files from my computer, I got a completely different result. This experiment shows that compressed files perform better. The reason for this is that my program needs to send this data through the Internet network. I assume you could achieve completely different results depending on the speed of your Internet connection. However, sometimes we need to send data across a network.
Method 3: Load data into BigQuery from the Pandas DataFrame
Another option that we can use is load_table_from_dataframe. This method supports loading data from a Pandas DataFrame directly into BigQuery. Why do we need to use it? It could be a clever method when we need to load it from a source that is not supported by BigQuery. We can simply add new columns to a DataFrame or clean data imported from files.
def load_dataframe(file: str):
job_config = bigquery.LoadJobConfig(
schema = schema,
write_disposition = 'WRITE_TRUNCATE'
)
start = time.time()
client = bigquery.Client()
dfs = DataFrames()
path = f"D:/temp/{file}"
func = file[file.rindex(".") + 1:]
data = getattr(dfs, func)(path)
name = file.replace(".","_")
print(f"DF:{name},{time.time() - start}")
job = client.load_table_from_dataframe(
data,
f"xxx.test.{name}",
job_config=job_config,
)
job.result()
print(f"Load:{name},{time.time() - start}")
return name, time.time() - start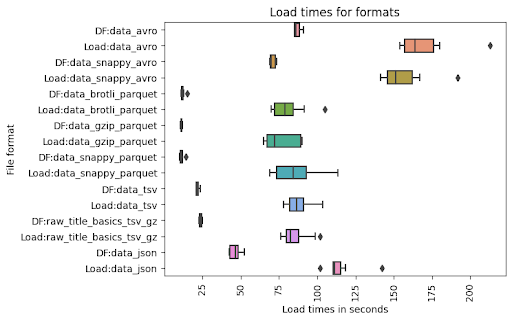
Data loading using Pandas DataFrame gives a very similar execution time. I have broken down indicators into DF (time to load DataFrame) and Load (time to load into BigQuery). The conclusion from the chart is that the Parquet format is the most effective format to read by Pandas. TSV files also have good performance. I was confused because of AVRO, but it occurred to me that the library pandavro that I decided to use, converts columns to strings when in the case of other formats it was an object. Apart from that, it means that Pandas is faster than pandavro. JSON wasn’t too fast mainly because of the time needed to load it into DataFrame.

Summary
The conclusion from this exercise is “it depends”. I suggest you analyze your use case and I hope this article will assist you in choosing the most appropriate method to load data into BigQuery.
Below I include additional material – the code that I used to test data loading to BigQuery. It presents all methods described in this article.
from google.cloud import bigquery
from google.cloud.bigquery import SchemaField
import time
import pandas as pd
from abc import ABC, abstractmethod
import pandavro as pdx
from google.api_core.exceptions import BadRequest
schema = []
schema.append(SchemaField("tconst", "STRING"))
schema.append(SchemaField("titleType", "STRING"))
schema.append(SchemaField("primaryTitle", "STRING"))
schema.append(SchemaField("originalTitle", "STRING"))
schema.append(SchemaField("isAdult", 'STRING'))
schema.append(SchemaField("startYear", 'STRING'))
schema.append(SchemaField("endYear", 'STRING'))
schema.append(SchemaField("runtimeMinutes", 'STRING'))
schema.append(SchemaField("genres", "STRING"))
config_dict = {
"csv" : bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.CSV,
skip_leading_rows=1,
autodetect=True,
field_delimiter="\t",
ignore_unknown_values=True,
quote_character="",
schema=schema,
write_disposition = 'WRITE_TRUNCATE'
),
"json" : bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
schema=schema,
write_disposition = 'WRITE_TRUNCATE'
),
"parquet" : bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.PARQUET,
schema = schema,
write_disposition = 'WRITE_TRUNCATE'
),
"avro" : bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.AVRO,
schema = schema,
write_disposition = 'WRITE_TRUNCATE'
)
}
class DataFrames():
def csv(self, name: str) -> pd.DataFrame:
return pd.read_csv(name, low_memory=False)
def gz(self, name: str) -> pd.DataFrame:
return pd.read_csv(name, low_memory=False, compression='gzip', sep='\t', quotechar='"')
def tsv(self, name: str) -> pd.DataFrame:
return pd.read_csv(name, sep='\t', low_memory=False)
def parquet(self, name: str) -> pd.DataFrame:
return pd.read_parquet(name)
def avro(self, name: str) -> pd.DataFrame:
return pdx.read_avro(name, na_dtypes=True)
def json(self, name: str) -> pd.DataFrame:
return pd.read_json(name, lines=True)
def load_dataframe(file: str):
job_config = bigquery.LoadJobConfig(
schema = schema,
write_disposition = 'WRITE_TRUNCATE'
)
start = time.time()
client = bigquery.Client()
dfs = DataFrames()
path = f"D:/temp/{file}"
func = file[file.rindex(".") + 1:]
data = getattr(dfs, func)(path)
name = file.replace(".","_")
# print(data.dtypes)
print(f"DF:{name},{time.time() - start}")
job = client.load_table_from_dataframe(
data,
f"xxxx.test.{name}",
job_config=job_config,
)
job.result()
print(f"Load:{name},{time.time() - start}")
return name, time.time() - start
def load_local(job_config, file):
start = time.time()
client = bigquery.Client()
path = f"D:/temp/{file}"
name = file.replace(".","_")
with open(path, "rb") as source_file:
job = client.load_table_from_file(
source_file,
f"xxxx.test.{name}",
job_config=job_config,
)
job.result()
print(f"{name},{time.time() - start}")
return name, time.time() - start
def load_from_bucket(job_config, file):
start = time.time()
client = bigquery.Client()
name = file.replace(".","_")
job = client.load_table_from_uri(
f"gs://lakemk/test_2/{file}",
f"xxxx.test.{name}_2",
job_config=job_config,
)
try:
job.result()
except BadRequest:
for error in job.errors:
print(error["message"])
print(f"{name},{time.time() - start}")
return name, time.time() - start
arr = [
['data.json', 'json']
#['data.avro','avro'],
#['data.snappy.avro','avro'],
#['data.brotli.parquet','parquet'],
#['data.gzip.parquet','parquet'],
#['data.snappy.parquet','parquet'],
#['data.tsv','csv'],
#['raw_title_basics.tsv.gz','csv']
]
test = []
for i in range(1,20):
for x in arr:
#test.append(load_local(config_dict[x[1]], x[0]))
test.append(load_dataframe(x[0]))
df = pd.DataFrame(test, columns=["file","time"])
df.to_csv(index=False)Check out other articles related to data engineering
Discover tips on how to make better use of technology in projects



