


- Mariusz Kujawski
- Read in 8 min.
Data orchestration is a process that organizes and manages your data pipelines. In the case of the Data Lake or Data Warehouse, it supports retrieving data from sources, transforming it, and loading it to a destination. Data pipelines contain several tasks that need to be executed to achieve the expected result. Retrieving data from sources is relatively straightforward. We need to integrate with them, import data, and then we have to transform and load data, which is more complex and requires dependencies between steps. Here we can use a tool that orchestrates tasks in a process. The GCP platform allows us to use Apache Airflow, but recently I found out that we could use GCP Workflows which are much cheaper.
GCP Workflows
GCP Workflows is a serverless engine that we can use in Google Cloud. It is a fully managed orchestrator and it doesn’t need infrastructure to work. We don’t pay for idle time, just for executions. According to GCP documentation, we can use it in several use cases, such as:
- App integration and microservice orchestration
- Business process automation
- Data and ML pipelines
- IT process automation
In this post, I’ll demonstrate how we can use GCP Workflows to build a cheap process to load data into the BigQuery data warehouse or create ML processes. Components that I decided to use:
- Workflows
- Cloud Run
- Container Registry
- Cloud Storage
- BigQuery
Cloud Run
Cloud Run is a platform that allows you to run your Dockerized code developed in any programming language. Cloud Run Services and Cloud Run Jobs are two ways to run code. With Cloud Run Services you can trigger the execution of your code using an HTTP endpoint. The purpose of a Cloud Run Job is to execute a job and finish it when the work is completed. Cloud Run Service can be really cheap because you only pay for CPU usage. To learn more about pricing, visit cloud.google.com/run/pricing.
Container Registry
The service hosts, manages, and secures Docker container images. You can use it in other GCP services like Compute Engine, CI/CD, and Cloud Run.
Cloud Storage
It’s a storage for your data in GCP platform that allows you to keep data in buckets. You can select different storage classes to manage your costs of storing data and latency.
BigQuery
It’s a serverless data warehouse that helps you manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence without worrying about infrastructure. It’s SQL based engine supporting transactions (ACID). It supports interfaces like the BiGQuery console and the command line tool. Developers can use client libraries that work with programming languages like Python, Java, JavaScript, and Go.
The sample use case
In terms of this article, I’ll present how to build a dockerized application. This will download a gzip file, infer a schema, load files into BigQuery tables, and transform them into a star schema model.
The first step will be to create a Docker file with Python. I will use this container as an environment to execute my Python scripts. I decided to use an example that I found in GCP tutorials. Here you can find instructions on how to create a Docker image that mounts a GCP bucket as a driver inside of your Docker image. You can get the Docker file from this location.
The next step is to create an HTTP endpoint. This will trigger my application actions like downloading files, loading a file into BigQuery, and transforming it using SQL in BigQuery.
import os
import signal
from flask import abort, Flask, redirect, request
import logging
import actions
app = Flask(__name__)
# Set config for file system path and filename prefix
mnt_dir = os.environ.get("MNT_DIR", "/mnt/nfs/filestore")
filename = os.environ.get("FILENAME", "test")
@app.route("/import", methods=["POST"])
def download():
url = request.get_json()["url"]
name = request.get_json()["name"]
logging.info(f"log: {url}")
actions.import_file(url, name, "/opt/share/raw/")
return name, 204
@app.route("/load", methods=["POST"])
def load():
name = request.get_json()["name"]
logging.info(f"log: {name}")
actions.load_file_to_bq(name, "/opt/share/raw/", "test", "gs://xxx/raw/")
return name, 204
@app.route("/exec", methods=["POST"])
def exec():
name = request.get_json()["name"]
logging.info(f"log: {name}")
result = actions.exec_bq_query(name)
return result, 204
def shutdown_handler(signal, frame):
"""SIGTERM handler"""
print("Caught SIGTERM signal.", flush=True)
return
signal.signal(signal.SIGTERM, shutdown_handler)
# To locally run the app
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))Once I created my main.py file, I added logic for my application in another file actions.py
from google.cloud import bigquery
import gzip
from google.cloud.bigquery import SchemaField
import time
import requests
import logging
def exec_bq_query(name: str) -> str:
client = bigquery.Client()
sql = ""
with open(name, "r") as file:
sql = file.read()
job = client.query(sql)
job.result()
return job.destination.table_id
def import_file(url: str, name: str, path: str) -> None:
start = time.time()
r = requests.get(url, stream=True)
with open(f"{path}{name}", "wb") as f:
for chunk in r.raw.stream(1024, decode_content=False):
if chunk:
f.write(chunk)
end = time.time()
logging.info(f"{end-start}")
def read_schema(name: str, path: str) -> str:
fields = []
with gzip.open(f"{path}{name}", "rt") as f:
for line in f:
fields = line.split("\t")
break
schema = []
for x in fields:
schema.append(SchemaField(x.replace("\n", ""), "STRING"))
return schema
def load_file_to_bq(name: str, path: str, bq_dataset: str, gcp_path: str) -> None:
client = bigquery.Client()
schema = read_schema(name, path)
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.CSV,
skip_leading_rows=1,
autodetect=True,
field_delimiter="\t",
ignore_unknown_values=True,
quote_character="",
schema=schema,
)
tab_name = name[: name.find(".")]
job = client.load_table_from_uri(
f"{gcp_path}{name}", f"{bq_dataset}.{tab_name}", job_config=job_config
)
job.result()I decided to use the IMDb dataset for this experiment. I have a function that downloads files from HTTP. I created a method that reads the headers of files to create table schemas. I tried to use the “autodetect” property in LoadJobConfiguration, but I faced issues with proper data interpretation. The root of the problem here is that the Python library only examines the first 500 rows. If you investigate files in the dataset you will see that for instance rating file has millions of rows. I can use load_table_from_uri to load data from the storage without having to load it into docker’s memory. When data are loaded I execute SQL queries that transform data and create or replace tables.
Docker deployment and the environment configuration
To configure our environment, we need to create a Cloud Storage bucket, as well as a BiQuery dataset and deploy the container to Cloud Run. I will explain how to do it in steps.
Create a bucket
gsutil mb -l REGION gs://BUCKET_NAME
gcloud iam service-accounts create service_account_name
gcloud projects add-iam-policy-binding PROJECT_ID
\
--member "serviceAccount:service_account_name@PROJECT_ID
.iam.gserviceaccount.com" \
--role "roles/storage.objectAdmin"Build image
docker build . -t gcp:v1
Debug application
docker run-v HOST_PATH:/app --env-file .env --privileged -p 8080:8080 gcp:v1
I use here a .env file where I keep environment variable values for my local development.
Build and deploy the container image to Cloud Run
gcloud beta run deploy download-app --source . `
--execution-environment gen2 `
--allow-unauthenticated `
--service-account service_account_name `
--update-env-vars BUCKET=XXX `
--update-env-vars MNT_DIR=/opt/shareData Transformation and Orchestration
The last step is to develop a workflow that will orchestrate the process. You can create it using the GCP console. The define workflow tab allows us to create a workflow using YAML notation. You can find my YAML file below.
main:
params: [input]
steps:
- innerLoop:
for:
value: items # innerLoopValue does not exist outside of innerLoop step
in: [{"url":"https://datasets.imdbws.com/name.basics.tsv.gz", "name": "name.tsv.gz"},
{"url":"https://datasets.imdbws.com/title.ratings.tsv.gz", "name": "title_ratings.tsv.gz"},
{"url":"https://datasets.imdbws.com/title.principals.tsv.gz", "name": "title_principals.tsv.gz"},
{"url":"https://datasets.imdbws.com/title.basics.tsv.gz", "name": "title_basics.tsv.gz"},
{"url":"https://datasets.imdbws.com/title.episode.tsv.gz", "name": "title_episode.tsv.gz"}
]
steps:
- innerLoopAssign:
assign:
- workflowScope: ${items}
- download_cr:
call: http.post
args:
url: https://xxx.a.run.app/import
auth:
type: OIDC
body:
"name": ${items.name}
"url": ${items.url}
- load_to_BQ:
call: http.post
args:
url: https://xxx.a.run.app/load
auth:
type: OIDC
body:
"name": ${items.name}
- dim_title:
call: http.post
args:
url: https://xxx.a.run.app/exec
auth:
type: OIDC
body:
"name": "dim_title.sql"
result: dim_tile_result
- fact_ratings:
call: http.post
args:
url: https://xxx.a.run.app/exec
auth:
type: OIDC
body:
"name": "fact_ratings.sql"
result: dim_tile_result
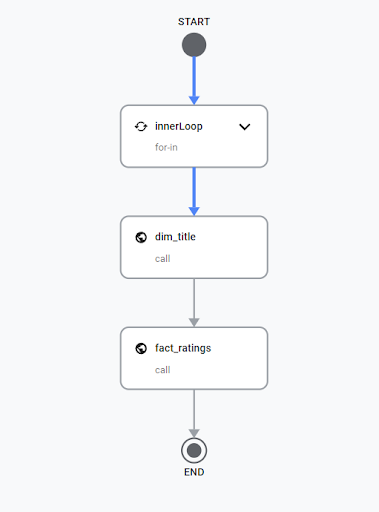
I will not get into details regarding the creation of steps in the workflow structure. You can find this information in the Workflow documentation. As you can see in the code I created the list of files that I need to import. Then we have a loop that downloads files. The next step is to load them into BigQuery tables. In the end, I call a script that executes SQL transformations.
CREATE OR REPLACE TABLE `xxx.test.dim_title` AS SELECT ROW_NUMBER() OVER() AS id, tconst, titleType, primaryTitle, originalTitle, isAdult, case when startYear='\n' then null else startYear end startYear, case when endYear='\n' then null else endYear end endYear, runtimeMinutes, genres, CURRENT_DATETIME() Create_timestamp FROM `xxx.test.title_basics`
Once our workflow is in place, we can test the entire process. In this way, I was able to create a simple process that would populate tables in my data warehouse. It is a very simple example with just two tables, but you can extend it by adding additional dimensions and fact tables to populate them in your data warehouse.
Machine Learning Use Case
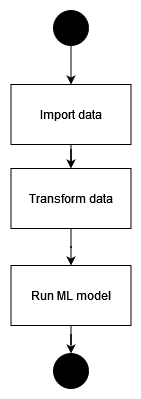
Another use case could be an ML process where you need to import data from SQL databases, REST API, or parquet files. Cleanse or transform the data. Once data is ready you can run a machine learning model that will find anomalies, classify your clients, find patterns, or forecast trends.
Summary
Orchestration is an important process in the data engineering world. It supports data pipelines and ML processes. The GCP platform provides many options for orchestration, including open-source tools or native tools like GCP composer and Workflows. In the case of Workflows, the advantage of this tool is that it’s serverless, which means that you don’t need to configure infrastructure for it. GCP composer is a powerful tool built on Python. Workflows are based on YAML and HTTP requests, therefore GCP Workflows are simple to use and quite cheap.
Looking for GCP solutions?
Check out our services and migrate with us to the next level



